多模态论文学习——Multimodal Foundation Models(一)
第一遍阅读
Abstract
本文关注于多模态基础模型的发展,根据领域发展是否成熟分成两类分别进行探讨:
- 成熟:通过学习vision backbones进行视觉理解和text-to-image;
- 待开发:LLM启发的统一视觉模型、多模态LLM的端到端训练、以及使用LLM链接多模态工具;
Conclusions and Research Trends
这里对上述的五个方向进行了总结,首先是经过较多预训练,利用零样本或者小样本从而实现转移到许多相同问题的真实模型。这里的较多预训练对应了之前提到的学习vixion backbones以及实现text-to-img。

这里的研究趋势我们不谈,在每个方面的研究方向介绍结束之后进行详细的调查。
第二遍阅读
相关知识
思想链(chain-of-thoughts)
大模型思维链(Chain-of-Thought)技术原理 - 知乎 (zhihu.com)
论文地址:https://arxiv.org/abs/2005.14165
提出的背景:三种不同的prompt方法(Zero-shot、One-shot、Few-shot),对于部分需要推理的问题大模型不能够work,于是提出了chain-of-toughts。
CoT 提示过程是一种最近开发的提示方法,它鼓励大语言模型解释其推理过程。思维链的主要思想是通过向大语言模型展示一些少量的 exapmles,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。


当然,上述方法依旧需要标注数据作为例子,针对零成本作者给出了Zero-shot-CoT,在问题的结尾添加think step by step的prompt可以让大模型逐步分析,实现自我增强的效果。
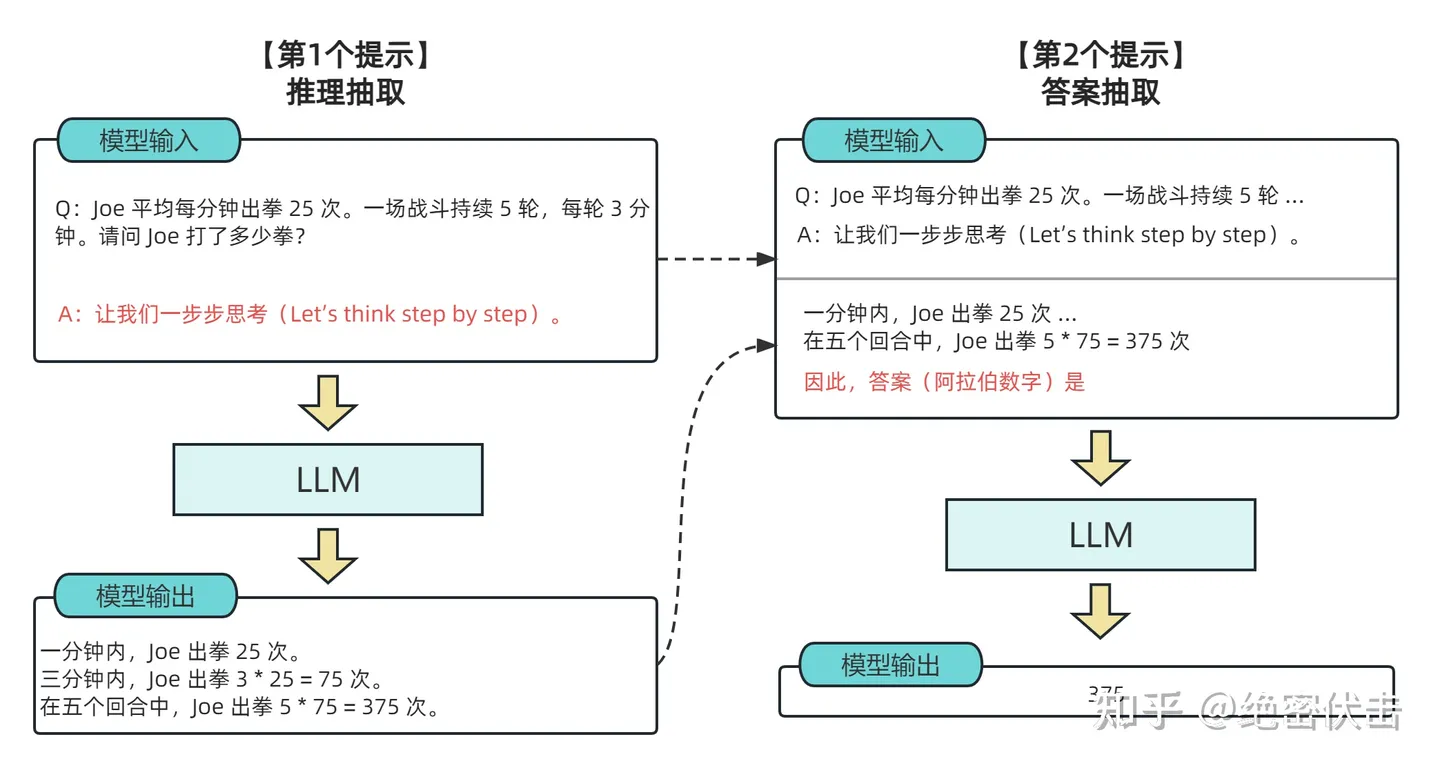
后续提出了改进的方法,即多路径step by step最后进行vote、对问题分解形成多个step by step状态。目前,思维链的应用在一些有限的领域,如学问题,五个常识推理基准(CommonsenseQA,StrategyQA,Date Understanding 和 Sports Understanding 以及 SayCan),对于其他类型的任务,如机器翻译,性能提升还有待评估。
后期也提出了Tree of Thoughts以及GoT等技术。
VLP模型
Introduction
首先介绍了过去十年人工智能在模型开发领域富有成效的历程:第一类类模型针对特定的任务,第二类模型通过大量的预训练,提高了语言理解和相关生成任务的性能;第三类模型通过将各种语言理解和生成任务统一到同一个模型中,从而生成新兴的能力,如上下文学习以及思想链。
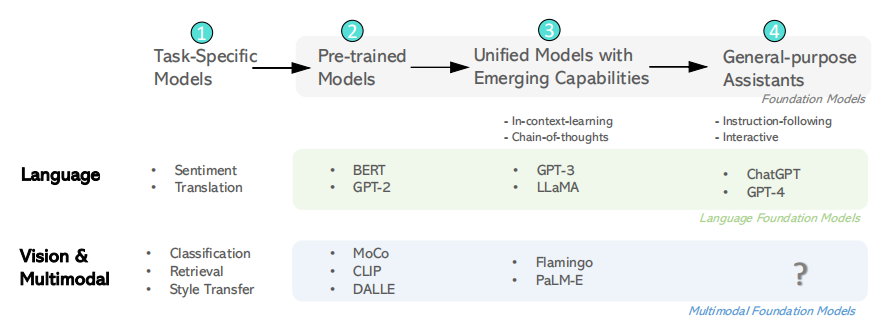
在本文我们将多模态基础模型的范围限制在视觉和视觉语言领域,包括以下三方面内容:
- 图像理解模型:自监督学习、segment anything;
- 图像生成模型;
- VLP;
多模态基础模型介绍
多模态基础模型关注的问题:视觉理解任务、视觉生成任务以及具有语言理解和生成的通用接口;
- 视觉理解模型:预训练一个强大的视觉主干是所有类型的计算机视觉下游任务的基础。(方向:图像级、区域级、像素级任务)
- 标签监督;
- 语言监督:CLIP、ALIGN,实现零样本图像分类;
- 图像自我监督:从图像本身挖掘监督信号学习图像表示:
- 多模态融合、区域级和像素级的预训练:这些方法依赖于预先训练的图像编码器或者预先训练的图像-文本编码器对;
- 视觉生成模型:由于大规模图像-文本生成模型,相关技术包括VAE、diffusion等方法:
- 基于文本的视觉生成:重点是生成正确的视觉内容,合成高保真的图像,以遵循文本的提示。
- 基于human-aligned的视觉生成;
- 通用的接口:
- 使用统一的视觉模型来理解、生成;
- 和LLM一起进行训练:通过将LLM的能力扩展到多模态设置和端到端训练模型;
- 使用LLM来进行链接,类似集成学习的方法构建融合模型,能够处理视觉信息的同时进行人机对话,产生类似人的反应;
整个文章的脉络图如下所示:
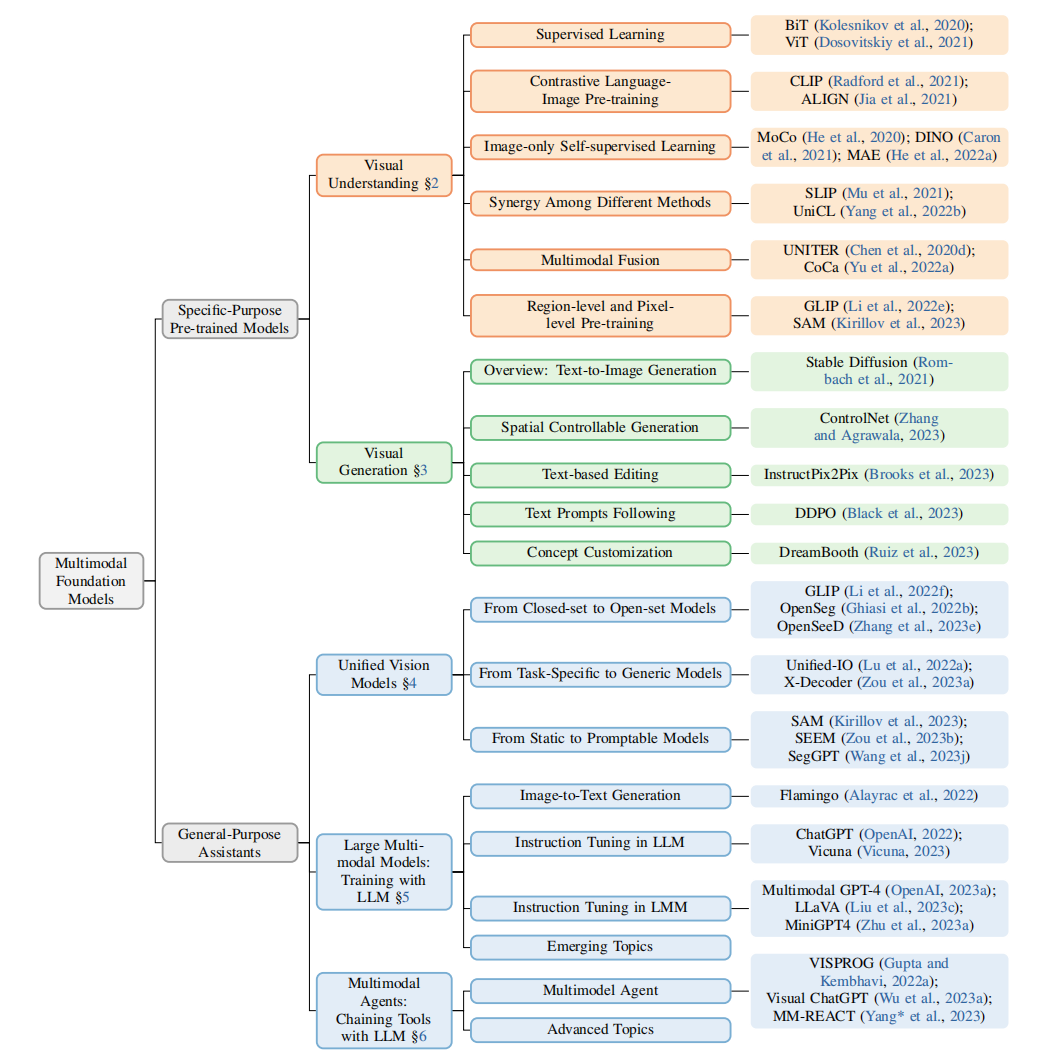
本文之后将从第三章开始进行分析,着重分析上述加粗部分。