多模态论文学习——Multimodal Foundation Models(二)
这一部分我们着重分析第三章内容,即视觉生成相关的技术前沿。视觉生成常用于图像、视频以及神经辐射场、3D点云等等,这里我们主要针对其在AIGC领域的发展。文本条件(如类标签、文本、边界框、布局掩码等等)对图像生成产生了十分深远的影响。
- T2I的发展现状与局限性;
- 加强T2I代对齐的目标领域:
- 空间可控T2I生成;
- 基于文本的图像编辑;
- 进一步遵循文本提示的图像生成;
- T2I的概念定制;
相关知识
AI Alignments
AI对齐要求ai系统的目标要和人类的价值观与利益对齐,保持一致。目前存在以下三个问题:
- 选择合适的价值观;
- 将价值观编码成为ai系统;
- 选择合适的数据进行训练;
在前期缺乏ai对齐的条件下,出现了寻找系统bug实现博弈最优解、多种设定目标冲突时做出错误取舍等问题。目前,Openai推出的InstructGPT预训练模型使用了人类反馈的强化学习技术,将人类的表现作为奖励信号,从而实现prompt tuning。
扩散模型相关论文:
(Sohl-Dickstein et al., 2015; Song and Ermon, 2020; Ho et al.,2020)
stable difusion:(Rombach et al., 2022)
Overview
Human Alignments in Visual Generation
ai对齐研究致力于遵循人类的意图来合成所需生成的视觉内容,目前的文献都在关注于简单T2I模型的某一特定缺点上:
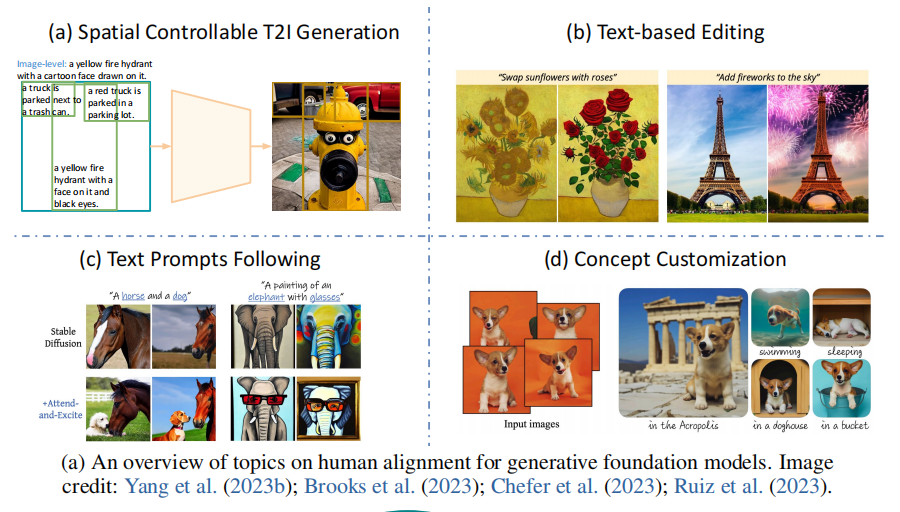
- 空间可控的T2I生成:将文本输入与其他条件结合,从而使得视觉生成的空间位置更加可控(Yanget al., 2023b; Li et al., 2023n; Zhang and Agrawala, 2023)
- 基于文本的图像编辑:从局部修改对象到调整全局的图像风格。(Brooks et al., 2023)
- 更好地遵循文本提示:普通的T2I模型可能会忽略某些文本描述,生成与输入文本不完全对应的图像,对此给出了改进的方法。(Feng et al., 2022b; Black et al., 2023)
- 视觉概念定制:在不同的环境中生成特定特征的图像,通过专门的token embedding或者conditioned image实现定制的模型 。(Ruiz et al., 2023; Chen et al., 2023f)
T2I发展历程
输入:文本;
输出:成对的图像作为输出;
技术:
- GAN:生成器和辨别器,二者相互竞争:生成器结合输入和噪声合成与语义相关的图像;辨别其对真实和合成图像进行区分;
- VAE:成对的编码器和解码器生成图像:编码器网络将图像的编码进行潜在表示,解码器实现潜在表示到图像的转化。目前的工作集中于:
- **Discrete image token prediction:**这个之前没有了解过,主要原理是成对的图像标记器和去标记器的组合,工作有VQGAN以及令牌预测等策略。之后可以了解一下。
- diffusion model:利用完全随机的图像来启动,在每次迭代预测之后去除一个噪声元素; (Sohl-Dickstein et al., 2015; Song and Ermon, 2020; Ho et al.,2020)
**下面对最广泛的开源T2I,即基于交叉注意力机制的文本图像融合Stable Diffusion进行介绍。**其主要构成是一个图像VAE、一个去噪的U-NET以及一个条件编码器。
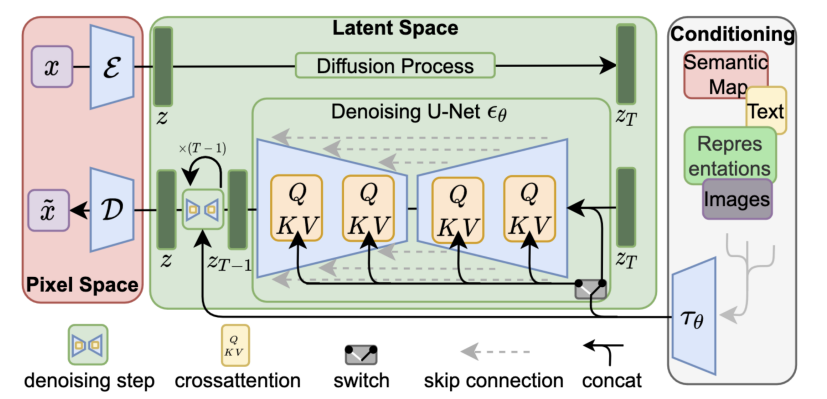
- VAE:将原始图像转换为潜在表示,在去噪的同时压缩潜空间,从而显著提高运算效率;
- 条件编码器:SD使用CLIP文本编辑器将输入文本转化为文本特征;
- 去噪U-Net:预测噪声,在每一次迭代之后去除该噪声,从而逐步将初始随机噪声演化为有意义的潜在图像;需要注意的是,在U-Net中的每个上下采样木块都有一个交叉注意力层和一个二维卷积层;
Spatial Controllable Generation
采用额外的空间输入条件来指导图像的生成。
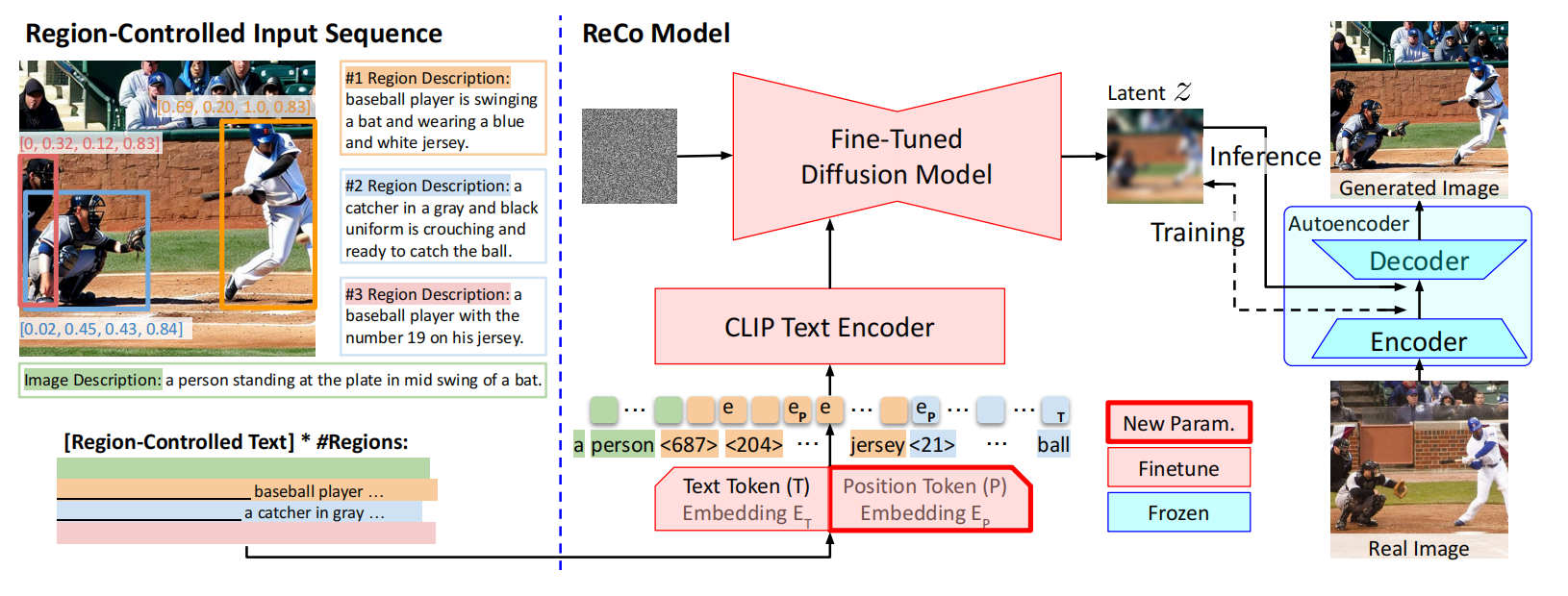
- 将普通T2I模型中的图像级文本描述扩展到基于区域的文本描述,ReCo是这个方向上最具有代表性的模型。
- 从box扩展到基于二维数组表示的密集空间:segmentation masks、边缘图和深度图等等,就是将额外的密集条件和视觉潜在性一起作为输入,然后进行训练的降采样初始化;
- 在ControlNet分支的输出合并回采样快之前,构建一个1×1的卷积层作为门控连接器,逐渐将额外的条件注入到预先训练好的SD中;(Zhang, L. and Agrawala, M. (2023). Adding conditional control to text-to-image diffusion models.arXiv preprint arXiv:2302.05543.)
- 不进行微调的空间控制:
Text-based Editing
关注于图像中的特定对象更改。
改变局部区域,或者在某个区域中添加一个对象:扩散模型中的逐步去噪一定程度上对应了图像编辑,这一部分主要关注对交叉注意力层的处理。
从空间编辑扩展到语言输入描述空间区域,给出期望的外观:输入的文本作为指令进行图像生成。目前最主要的问题是图和生成成对的编辑数据:
LMM方法:(Brooks, T., Holynski, A., and Efros, A. A. (2023 Instructpix2pix: Learning to follow image editing instructions. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, pages 18392–18402.)
Promt2提示:(Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., and Cohen-or, D. (2022). Prompt�
to-prompt image editing with cross-attention control. In The Eleventh International Conference
on Learning Representations.)
CM3Leon:(Wu, C., Yin, S., Qi, W., Wang, X., Tang, Z., and Duan, N. (2023a). Visual chatgpt: Talking, drawing
and editing with visual foundation models. arXiv preprint arXiv:2303.04671.)
系统集成不同的专门模块生成;使用外部预先训练的模型进行编辑;
VisualChatGPT:(Wu, C., Yin, S., Qi, W., Wang, X., Tang, Z., and Duan, N. (2023a). Visual chatgpt: Talking, drawing
and editing with visual foundation models. arXiv preprint arXiv:2303.04671.)
Text Prompts Following
当文本输入较为复杂时,生成图像的过程中可能忽略了部分特征。这里关注点在于交叉注意力层的重构以及图像文本相似性的正则计算。
- 重新分配潜在表达和图像-文本交叉注意,使更多的文本名词短语保存在图像中;
- 以图像-文本相似性作为惩罚;