InstructBLIP
代码地址:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
前言
这里主要对其数据构建的方法进行深入的研究,同时对基座模型BLIP-2进行了解,最后对源码进行分析。重点章节为Vision-Language Instruction Tuning。
相关知识
held-in and held-out
前者代表用于训练模型的数据集,通常是原始数据集中随机抽取一部分数据;而后者用于评估模型性能、泛化能力。
多模态数据集的构建方法
指令数据集:
将现有的NLP数据集转换成指令格式来收集指令调整数据 [46, 7, 35, 45]或者LLM生成指令数据[2, 13, 44, 40];生成的指令混合训练。
BLIP
BLIP(Bootstrapping Language-Image Pretraining):引入了跨模态的编码器和解码器,实现了跨模态信息流动。
MED架构
编码器-解码器的多模态混合结构MED,进行多任务预学习和迁移学习,其中包括两个单模态编码器、一个以图像为基础的编码器和一个以图像为基础的解码器。
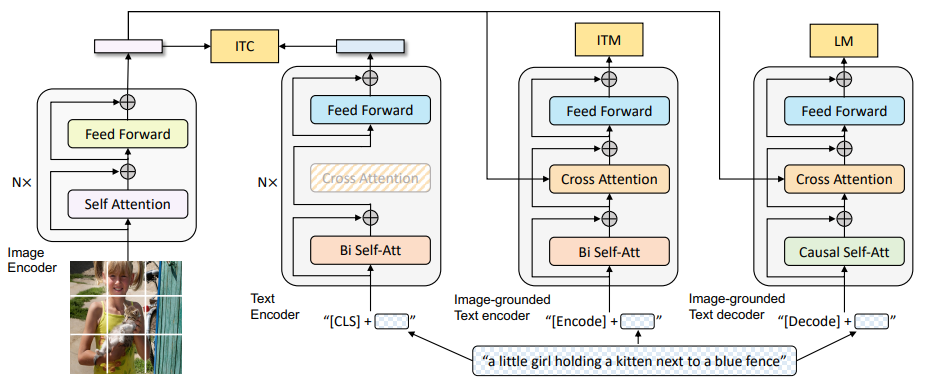
首先分别对image和text进行encode,经过自注意力、前向传播后计算ITC损失(图像-文本对比损失,对齐图像和文本的潜在特征空间)。之后就是对比学习的过程,将text和image同时编码后计算ITM(对图文匹配性进行二分类,也就是正负样本的训练,建模图文多模态信息的相关性)。最后解码,通过交叉熵进行优化,训练模型自回归生成目标(LM损失)。
CapFilt
数据集中的数据集存在噪音以及无匹配图片的问题,因此引入了cationer和Filter进行处理:
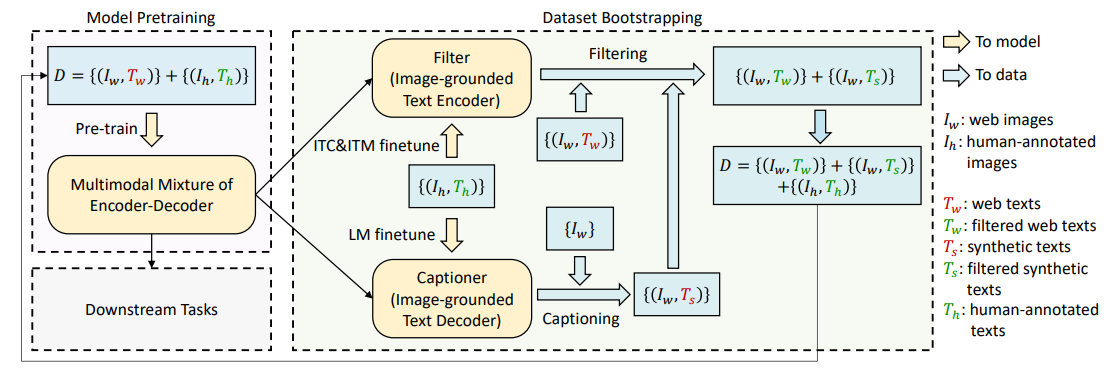
Filter和caption都是通过预训练模型得到的,过滤存在噪音的IT对,同时生成缺失的text。
BLIP-2
BLIP-2由预训练的image encoder、预训练的LLM,和一个可学习的Q-Former组成。
self.vision_model = Blip2VisionModel(config.vision_config)
self.query_tokens = nn.Parameter(torch.zeros(1, config.num_query_tokens, config.qformer_config.hidden_size))
self.qformer = Blip2QFormerModel(config.qformer_config)
self.language_projection = nn.Linear(config.qformer_config.hidden_size, config.text_config.hidden_size)
if config.use_decoder_only_language_model:
language_model = AutoModelForCausalLM.from_config(config.text_config)
else:
language_model = AutoModelForSeq2SeqLM.from_config(config.text_config)
self.language_model = language_model
其模型的架构如下图所示:
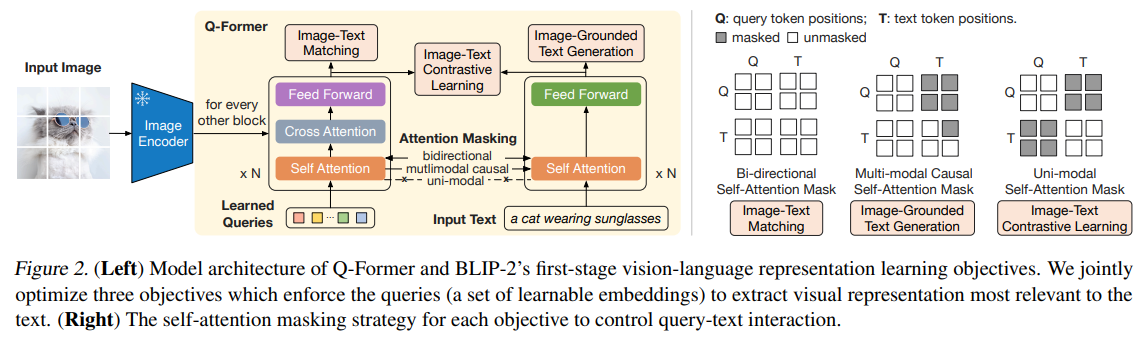
需要注意的是,在1中出现的三种loss都发生了变化:
- ITC:采用了单模态的自注意力掩码,不允许Query和Text相互注意。具体来说就是计算每个Query的嵌入和text嵌入的相似度从而完成匹配;
- ITG(Image-grounded Text Generation):基于图像的文本生成。在Q-Former生成文本时,ITG采用多模态的注意力机制掩码来控制Query和Text的交互,Query可以相互关注,但是不能关注Text标记每个Text标记都可以处理所有Query以及前面的Text标记。
- ITM:对比学习匹配过程。
Prompt-Tuning,Instruction-Tuning,CoT
prompt:特定任务中对预测结果进行mask(类似于bert)就是一种prompt方法,即利用LLM的生成能力帮我们完成任务,让模型输出我们想要的内容;
instruction:告诉模型如何处理数据或者执行某个操作,不是简单的上下文。其基本流程如下所示:
- 准备自然语言指令集:描述任务类型和任务目标:“该文本的情感是正面还是负面的”;
- 训练数据集:标注正面和负面;
- 模型输入:指令和数据集拼接作为输入;
- 在指令上进行微调,满足特定任务;
CoT:将生成任务分解成较小、相互关联的任务,帮助模型理解和生成连贯、上下文感知的响应。
Abstract
背景:额外的视觉指令对通用视觉语言模型具有一定挑战;
创新:基于BLIP-2模型对视觉语言指令调整进行研究。
- 26个公开数据集,将其转换为指令调整格式;
- 指令感知查询转换器,根据给定的指令提取特征信息;
结果:13个数据集实现zeroshot,下游任务表现较好;
Introduction
本文的基座模型就是BLIP-2,其基本架构没有变化。
贡献:
- 对视觉语言指令调整进行了全面研究,将26个数据集转换为指令微调模式;
- 文本指令不仅仅提供给LLM,也提供给Q-Former,使得其从冻结的图像编码器中提取指令感知的视觉特征;
- LLM的使用:FlanT5、Viuna;
Vision-Language Instruction Tuning
在以下的数据集上都实现了指令微调;
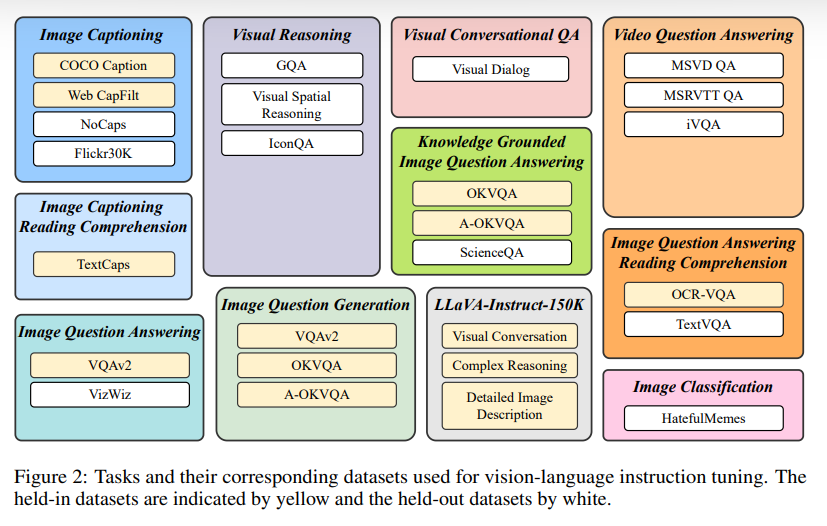
小部分数据作为held-out评估模型最后的zeroshot性能。在指令微调过程中,对每个数据集统一混合所有训练集和样本指令;在场景文本中还会添加OCR标记作为补充信息。
指令感知视觉特征提取
背景:BLIP-2直接将静态的图像特征输入LLM,因此给出了改进:
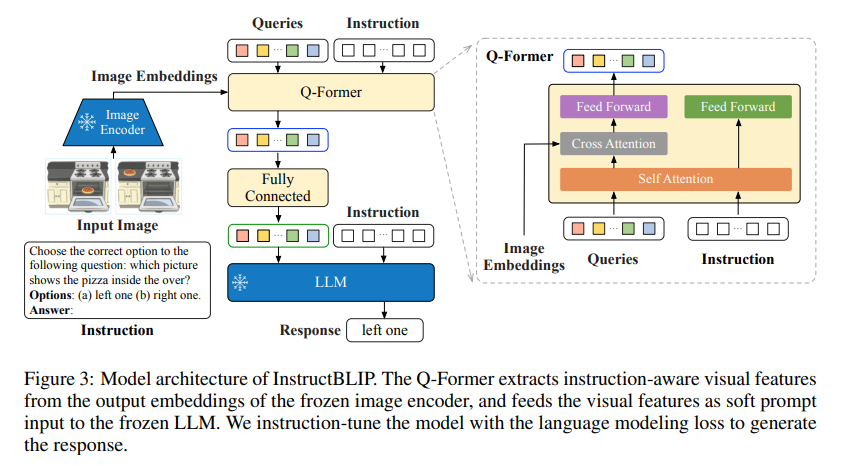
和BLIP-2不同的是,增加了指令和请求的自注意力计算过程,激励提取与任务相关的图像特征,将结果和图像嵌入进行交叉注意力计算;
推断方法
直接提示经过指令调整的模型生成响应(生成任务)。对于分类任务,使用词汇排序法(限制生成答案数量,对数似然选择topk)、扩充正负样本标签等等。
Experiments
在消融实验的过程中,发现在空间视觉推理或者时间视觉推理的数据集中,性能的下降更为严重;
BLIP相较于其他多模态模型,能够自适应调整生成文本的长度来满足用户的意图;
Conclusion
应用于复杂视觉推理、VQA、下游任务初始化。