MAE论文精读
前言
这一部分算是diffusion基础论文的后记,用来记录ViT的相关工作。在CLIP的image encoder中使用了ViT,因此在此进行拓展,后续会补充对源码的学习。
相关知识

可以理解为MAE是ViT的一个拓展研究,在视觉领域进行深入的研究。
论文:Masked Autoencoders Are Scalable Vision Learners
Abstract
基本思想来自于bert的masked思想,对某一个小图像块进行masked(patch),然后重新构建确实的像素,创新的架构如下:
- 一种非对称的编码器-解码器架构:编码器对无masked标记的patch进行编码,轻量级解码器根据潜在表示和masked标记重建原始图像;
- 自监督训练的实现:对输入图像的高比例像素进行掩码会产生一个有意义、简单的自我监督任务;这里也说明了bert为什么不能进行多个mask。
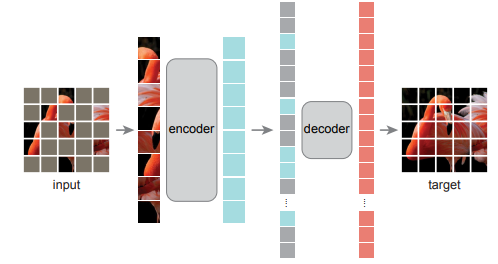
MAE的模型架构如上图所示,其中灰色的部分即为被masked的部分。对未被masked的数据进行encode,转化为拉长向量,然后将masked部分进行插入,解码器进行重构。
Introduction
背景:将bert引入视觉领域的工作已经有了,但是都发现效果和NLP领域相差甚远。作者认为可以从以下三个方面进行改进:
- 视觉领域的卷积网络不能对位置编码进行合适的嵌入;
- 图像的信息密度和文字的信息密度不同:每个单词具有一定的含义,但是大多数像素点往往不具备足够的信息量;
- decoder的架构缺陷:在文字的decoder中输出的往往是包含各种语义的单词,而图像decoder的输出不具备高信息。
因此,本文实现了非对称的encoder-decoder模型,采用高比率的mask。
MAE形式上也是一种去噪获取图像的方法。
Approach
Masking部分
按照均匀分布进行较高遮蔽率的随机采样,解决了图片像素高度冗余的问题。
MAE编码器
在进行编码过程时,先将masked数据进行移除(这里移除的时候应该含有位置信息)。
MAE解码器
解码器只应用于pretrain,其输入为已编码patch和mask标记组成的向量集合。
重建过程
对mask部分进行重建,解码器输出代表mask的像素值向量,损失通过每个patch的内部像素MSE实现。
简单的采样操作
- 对图像划分patch,每个patch进行位置编码操作;
- shuffle一下所有的patch,根据屏蔽率进行mask提取;
- encode过程;
- mask和原集合合并,进行decoder计算;
Discussion and Conclusion
在计算机视觉领域,监督方法往往占据了大头,本文提出的一种类似于NLP技术的自监督方法提供了一个新的开发领域。
虽然可以对这一领域进行深入研究,但是这种类似NLP的技术还是存在一些问题:
- 分割方法的缺点:图像分割得到的patch并不能像单词或者短语一样表达一个具体的含义,不具备语义分割的功能;
- 视觉概念的学习:对于模型而言,是否真的对视觉信息进行了学习?虽然结果十分出色,但是重建之后的图像是否和NLP一样具有一定的整体含义,这还需要进行深入的研究;