stable diffusion论文基础篇
前言
论文:High-resolution image synthesis with latent diffusion models
code:https://github.com/CompVis/latent-diffusion
这一部分也是对diffusion基础论文学习篇的拓展,算是在综述中总结的diffusion学习的第二阶段,之后会对之前提到的四个方向分别进行剖析,在细化领域分析之前,我会对diffusion的代码部分进行系统的学习。
相关知识
图像压缩方法
- patch-based:一种基于图像块的压缩方法,这种方法将图像分成多个小块,然后对每个小块进行压缩。
- 基于感知损失:对图像进行变换、量化和编码等步骤,将图像压缩到较小的体积。
VQ-GAN
这里主要介绍矢量量化层的应用。在本文中,使用该方法对压缩后的图片进行惩罚。具体来讲,矢量量化层适用于将连续的特征向量量化为离散的向量,每个特征向量映射到最近的离散向量,然后将这些离散向量作为解码器的输入。其计算过程可以用以下的公式进行表示:
q(z)=k=1∑Kwkδ(z−ek)
其中,w为离散向量e的权重,z代表某个连续的特征向量。
FID
FID是一种用于评估图像生成模型的指标,衡量生成图像与真实图像之间的差异。FID越小,代表生成图像和真实图像之间的差异越小。
FID(x,g)=∣∣μx−μg∣∣22+Tr(Σx+Σg−2(ΣxΣg)1/2)
其中,∑x代表真实分布的协方差矩阵,∑y代表预测分布的协方差矩阵。
Inception Score
评估生成图像质量的指标,使用预训练后的Inception v3模型对抽样的生成图片进行分类,根据每个图像,计算其类别概率分布的熵,最后平均一下得到指标IS。IS的值越高,生成的图像的质量越高。
内容分析
Abstract
过去diffusion模型中存在的问题:
- 优化成本高:去噪的过程通常直接在像素空间中,导致优化时需要更改的参数较多;
- 推理成本高:顺序推理,同时在每次训练结束都有顺序评价;
针对以上的问题,本文提出了创新点用于提升效率:
- 找到降低模型复杂度和保留图像细节的平衡点:预训练编码器潜在空间应用diffusion;
- 提高灵活性:在架构中引入交叉注意力层;
Introduction
**背景:**GAN目前的工作大多数局限于有限的数据,当数据量增大GAN很难实现更好的判别,因此对抗学习不适合多模态的分析。此外,DM发展迅猛,即使是无条件的DM也能完成特定工作,大量的参数共享使得他们不会出现GAN的模式崩溃问题。
**DM发展面临的问题:**参数数量过大:通过大量的参数实现对数据难以察觉的细节进行建模,即使引入欠采样计算成本也很大;
潜在diffusion模型的引入:
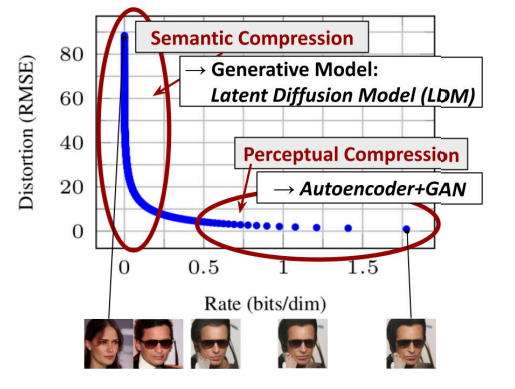
上图对训练后的模型速度-失真的权衡进行了描述。**潜在扩散模型,顾名思义,就是将整体的数据投影到低维空间,在保证数据特征保留和空间维度之间的平衡性之后,在潜在空间中进行训练。**因此,这个将数据投影的自动编码器的实现就十分重要了。
那么,文本到图像应该如何实现呢?本文设计了一种新的架构,将transformer连接到DM的UNET主干网,使用任意类型的基于标记的调节机制。
这里不对GAN和VAE进行过多的阐述,最近扩散模型在密度估计和样本质量方面取得了先进的成果。但是DM在扩散过程中会产生特征的损失,为了提升图像的质量导致训练的成本较高,最终的推理速度也比较慢。本文解决了这一问题,通过将卷积backbone扩展到更高维度的空间当中。

Method
作者首先指出了以往工作的局限性,即使用的下采样方法无法解决参数过多的问题。作者将学习阶段和生成阶段的压缩分开来进行分析,使用自动编码模型分析:
- 离开高维空间进行DM,和低维空间的下采样匹配;
- 利用DM从UNET模型中集成下来的归纳偏置,使得数据压缩的需求下降;
- 通用压缩模型在潜在空间可用于训练多个生成模型,同时可以应用于下游的应用;
感知图像压缩
基本方法:感知损失和基于patch-based的组合训练方法实现。
评价指标:基本目标是为了避免高方差的潜空间,方法是使用KL-REG和VQ-REG两个变量进行分析:
- KL-REG:类似于VAE,增加KL散度惩罚在潜在空间分布和标准分布之间;
- VQ-REG:矢量量化层规范解码器的输入;
latent diffusion models
有了感知图像压缩的encoder和decoder,可以高效地访问低维的潜在空间。与之前的diffusion model不同的是,本文通过串联交叉注意力机制对LDM进行调节。此外,结果和原图像的损失计算上,关注于潜在空间表示的分布。原始公式和改进的公式如下:
LDM=Ex,ϵ∼N(0,1),t[∥ϵ−ϵθ(xt,t)∥22],
LLDM:=EE(x),ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t)∥22].
conditioning mechanisms
背景:以往的diffusion模型依赖于文本、语义图等输入对扩散过程进行约束,但是在图像合成方面除了类标签或图像模糊变体等方法以外,没有其他的方法。
创新点:提出了有效学习各种输入模态的注意力模型,其中的QKV表示如下:
Attention(Q,K,V)~=softmax(dQKT)⋅V
Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y).
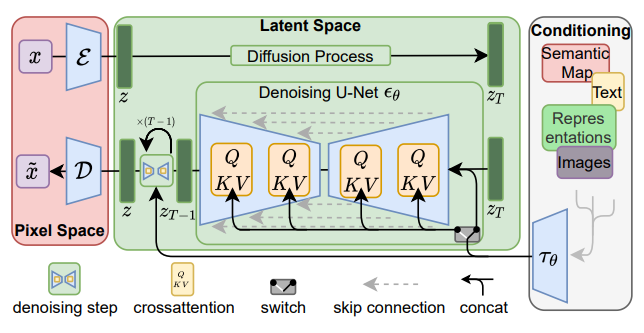
其中Q应用的数据为UNET的潜在空间表示,K和V应用的是生成图片的多模态信息。下图可以更为深入地理解这一过程:
Experiments
对数据集使用不同的下采样因子随着训练的变化研究:
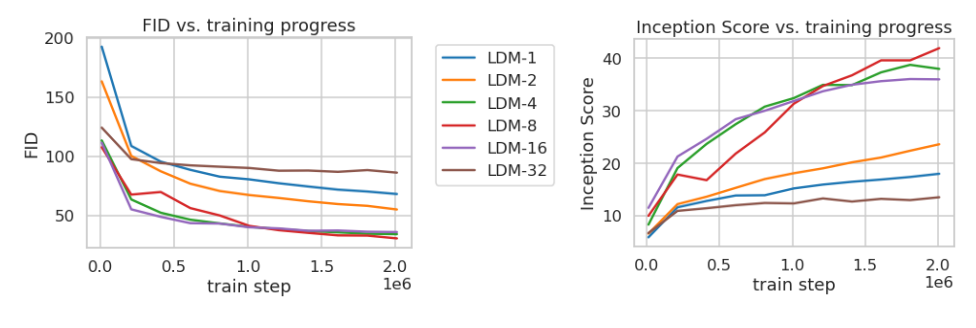
其中,LDM-1代表基于像素的扩散模型,后面的数字代表下采样因子,指每个采样步骤中图像分辨率的缩小比率。可以看到,LDM-(4-16)在效率和感知方向上得到了平衡。
之后是对样本吞吐量的研究,吞吐量指的是每次DDIM进行采样时的速度。
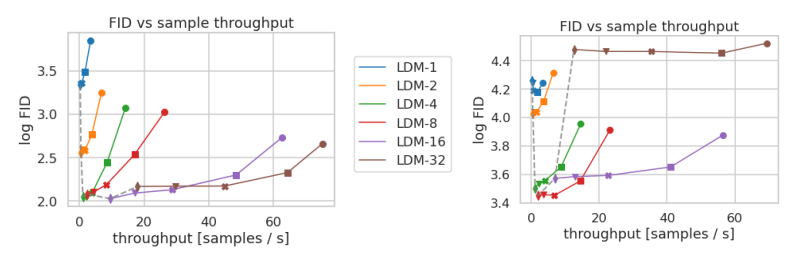
可以看到,LDM-4和LDM-8在吞吐量的表现上也十分出色。
此外,作者还对其他创新点的提升进行了介绍:
- condition latent diffusion:注意力机制的引入能够对用户的文本进行概括,同时使得模型拥有生成超分辨率的图片;
- 图像压缩方法的创新:以往的简单图像回归模型能够实现较高的SSIM分数,但是不能符合人类的感知。现在基于感知损失和patch-based方法处理后,预测得到的图片能够获得很高的人类感知分数。
- 结合latent diffusion的内部填充:基于像素的latent diffusion和基于上述两种正则方法的LDM-4能够很好地将图片中的缺失部分进行补齐。

Conclusion
模型泛化性很强,在多个图像生成任务重取得了很好的成果。
评价
确实是很不错,得亏之前补了一下diffusion的知识,整篇论文读下来非常的顺畅,只是在图像评价标准部分查询了不少的知识。之后会对相关的代码进行分析,最好手撸一遍。