论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
相关知识
FPN(特征金字塔)
基本原理:生成不同尺寸的图片,每张图片生成不同的特征,分别进行预测,最后统计所有尺寸的预测结果。
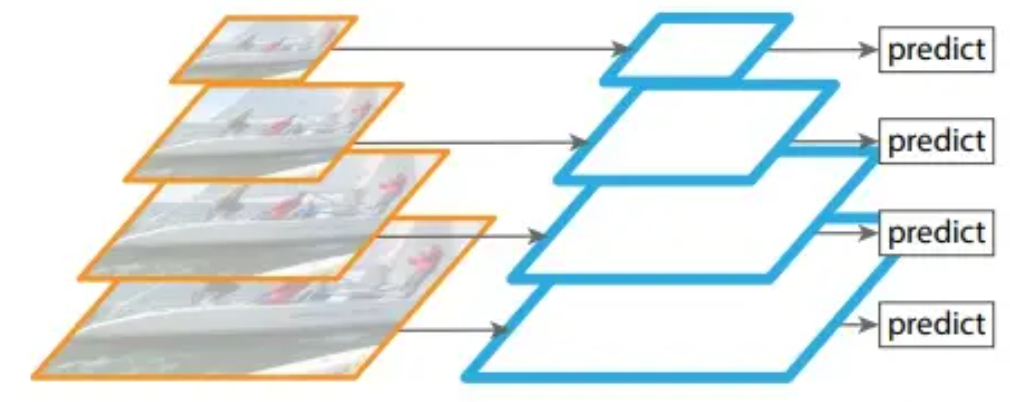
作用:把高层的特征传下来,同时保证底层特征也能被记录,最终提取多尺度的特征图。通过这种操作可以获得高分辨率、强语义的特征,有利于小目标的检测。
Abstract
相当于ViT的延伸,背景:
实现方法:提出了一种分层变换器,移位窗口实现,移动的窗口保证了相邻的自注意力计算存在重叠部分,从而提高了效率。最终的模型在图像分类和密集预测任务中表现较好。
Introduction
和ViT那篇差不多,讲了一下当前cv的两种方式,即传统的CNN和引入NLP的transformer。在本文中作者希望将ViT改进成适合所有图像任务的通用骨干网络。
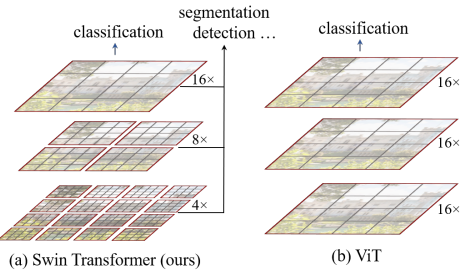
相较于之前的架构,构建分层特征图,并且具有与图像大小线性的计算复杂度。如图 1(a) 所示,Swin Transformer 通过从小尺寸补丁(灰色轮廓)开始并逐渐合并更深 Transformer 层中的相邻补丁来构建分层表示。借助这些分层特征图,Swin Transformer 模型可以方便地利用先进技术进行密集预测,例如特征金字塔网络 (FPN)或 U-Net。
滑动窗口的设计不仅能够使相邻patch之间的注意力计算成为可能,同时利用空间局限性提高了内存使用效率。
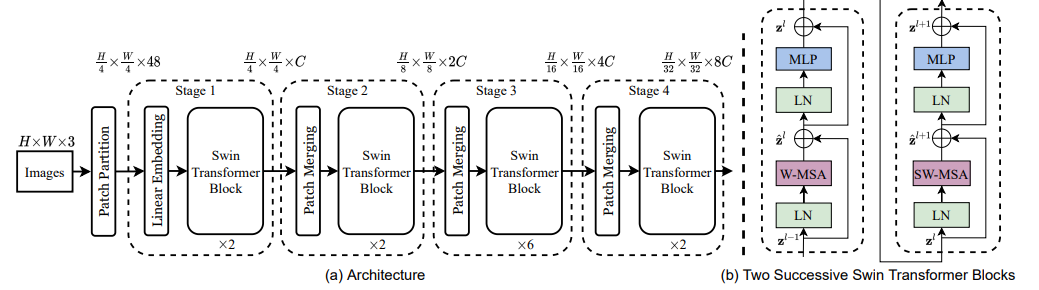
Method
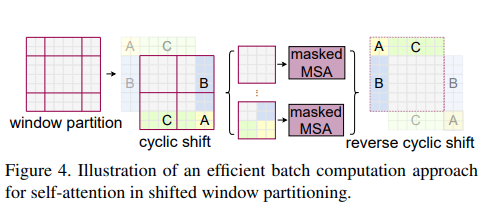
在滑动窗口的实现过程中,需要注意非相邻的自注意力计算问题,这时候就需要对包含不同部分的位移后patch进行masked操作。
Conclusion
该方法能获得更多层次的特征和更小的计算复杂度,取得了很好的成果。但是对于多模态领域而言,想要实现视觉和语言的统一,还需要探索Swin Transformer在NLP领域的可行性(即滑动窗口的方法)