Progressive Backdoor Erasing via connecting Backdoor and Adversarial Attacks
相关知识
整体框架
Abstract
背景:深度学习网络容易受到两种攻击:后门攻击和对抗性攻击。以往的研究将其作为独立的问题进行研究。
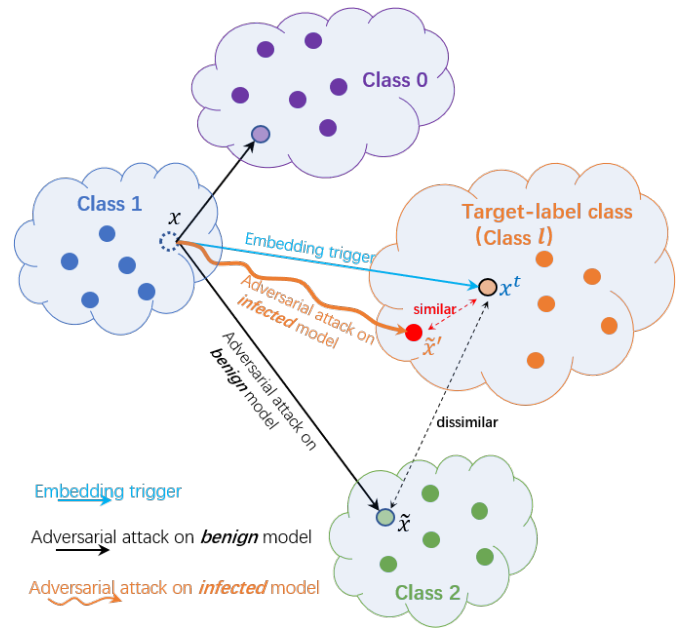
问题:对于植入后门的模型,对抗样本生成与它触发的图像具有相似的行为,说明一个模型中植入一个后门会显著影响模型的对抗样本生成。
方案:提出渐进式后门擦除算法(PBE,Progressive Backdoor Erasing),利用非目标的对抗性攻击来逐步净化受感染的模型,对干净的样本没有明显的性能下降。
Introduction
DNNs在许多领域得到了广泛应用(人脸识别、自动驾驶),因此其安全性显得尤为重要。DNNs在其推理和训练阶段都容易受到威胁。
- 训练阶段:训练阶段将后门嵌入到模型中。当一个预先定义的trigger嵌入测试集图片时,受感染的模型就会将测试图像错误地分类。
- 推理阶段:数据集中加入对抗性样本,用小的对抗性扰动使模型进行错误的判断。
特别的,我们观察到,对于一个植入了后门的模型,他的对抗样本生成和他触发的图像有相似的行为。对于正常的模型,其对抗性样本的预测类标签服从均匀分布;对于感染的模型,对抗性样本可能被预测为后门标签。(无论是怎样的target标签、后门攻击设置以及触发嵌入机制)
发现:通过植入trigger对抗图像发生了显著的变化,两者都激活了相同的DNN神经元子集。
近些年来后门攻击取得了巨大的进步,从可见的触发到隐形触发,从中毒标签到清洁标签攻击。(WaNet),相对的后门防御方法研究存在一定的滞后性,此外还需要一个干净的额外数据集来从受感染的模型中清除后门。
**本文提出了一种新的基于联系的防御方法:**在开始时,训练数据(包含中毒图像)被随机采样,以建立一个初始的额外数据集。接下来,我们使用它们,通过利用对抗性攻击技术来净化受感染的模型。然后,利用纯化的模型从训练数据中识别干净的图像,用于更新额外的数据集。通过交替程序,感染模型和额外的数据集逐步纯化。
主要的贡献:
我们观察到后门攻击和对抗性攻击之间的潜在联系,即,对于一个受感染的模型,它的对抗性例子与它所触发的样本有相似的行为。并通过理论分析来证明我们所观察到的结果。根据我们的观察,我们提出了一种渐进的后门防御方法,即使没有干净的额外数据集,也能达到最先进的防御性能。
为什么会产生这种现象?(即对感染的模型进行对抗性样本攻击会导致预测结果更好,达到净化模型的目的)
后门被植入一个模型时,一些DNN神经元会被触发器激活,这被称为“后门神经元”[5]。当对受感染的模型进行对抗性攻击时,这些“后门神经元”更有可能被选择/锁定和激活,以产生对抗性的例子。因此,生成的对抗性例子可以像触发的图像一样工作。
Conclusion
对抗攻击和后门攻击之间的存在内部联系,这种联系可以被用来构造防御方法。
总结