作业二实验报告
重要的库
import requests
from bs4 import BeautifulSoup
import os
import pandas as pd
import random
from pyecharts import options as opts
from pyecharts.charts import WordCloud, Pie, Bar, Line, Grid
from pyecharts.globals import ThemeType
数据爬取
根据题干要求,爬取平凡的荣耀中所有演员的词条信息以及对应外链的信息,同时获取浙江卫视、东方卫视的收视率数据。整体的步骤如下:
- 获取所有演员相关的html代码;
- 依旧遍历每个演员对应的html代码,保存每个演员的姓名以及相关链接;
- 根据保存的外链,爬取每个演员对应的基本信息;
- 爬取收视率表格;
- 将上述数据分别存储为csv文件;
- 爬取演员词条中对应演员的照片,存储为jpg文件;
获取所有演员名单以及相关信息
相关函数/对象:
- get_data(url)
- process(data)

这一部分使用的仍是BeautifulSoup以及requests中的库函数进行数据爬取。步骤如下:
- 爬取标签为dl,属性为{‘class’: ‘info’}的相关html代码;
- 查找演员姓名以及对应链接;
- 对于演员姓名,直接选择每组dl中的dt.text;
- 对于链接,每个dl标签中只含有一个href属性,因此只需要截取所有dl中的标签为a属性为href的内容即可;
- 利用得到的外部链接,爬取每个演员的标签为div,属性为{‘class’: ‘basic-info J-basic-info cmn-clearfix’}的html代码;
- 同上一题,对内部的dt,dl标签进行遍历,得到每个演员基本信息字典;
- 将字典汇总,获得整体数据,等待数据处理。
代码如下:
def get_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.99 Safari/537.36 '
}
html = requests.get(url, headers=headers)
html.encoding = "utf-8"
bs = BeautifulSoup(html.text, "html.parser")
results = bs.find_all('dl', {'class': 'info'})
stars = []
for res in results:
star = {}
star['name'] = res.find('dt').text
link = res.find('a')
if link is None:
star['中文名'] = res.find('dt').text
stars.append(star)
print("len(stars): {}".format(len(stars)))
continue
else:
star['link'] = 'https://baike.baidu.com' + link.get('href')
html_1 = requests.get(star["link"], headers=headers)
html_1.encoding = "utf-8"
bs_1 = BeautifulSoup(html_1.text, "html.parser")
result_1 = bs_1.find('div', {'class': 'basic-info J-basic-info cmn-clearfix'})
dt = result_1.find_all('dt')
dd = result_1.find_all('dd')
item = 0
for t in dt:
index = "".join(t.text.split())
star[index] = dd[item].text.strip()
item += 1
stars.append(star)
print("len(stars): {}".format(len(stars)))
result_answer = pd.DataFrame(stars)
return result_answer
获取演员图片
相关函数/对象:
- get_pic(url, name, bs)
- pic_check(pics)
- process.get_star_pic(self)
根据演员的相关链接,爬取img标签属性为{‘alt’: 演员姓名}或者{‘class’: ‘picture’}的src属性,调用pic_check函数进行链接筛选,去除其他非链接的src值,得到图片链接,将图片保存到指定文件夹。代码如下:
def get_pic(url, name, bs):
pics = bs.find_all('img', {'class': 'picture'})
urls = pic_check(pics)
if len(urls) == 0:
pics = bs.find_all('img', {'alt': name})
urls = pic_check(pics)
for i, url in enumerate(urls):
path = 'data/' + 'pics/' + name + '/'
if not os.path.exists(path):
os.makedirs(path)
picture = requests.get(url, timeout=15)
pic_path = str(i + 1) + '.jpg'
with open(path + pic_path, 'wb') as f:
f.write(picture.content)
获取收视率等信息
相关函数/对象:
get_table(url)

根据百度百科的显示,收视率数据主要是来自于浙江卫视和东方卫视,因此只需要爬取收视情况即可。爬取的过程如下:
- 通过观察前端代码可知,爬取标签为table,属性为{‘log-set-param’:‘table_view’,‘data-sort’:‘sortDisabled’}的数据即可;
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.99 Safari/537.36 '
}
html = requests.get(url, headers=headers)
html.encoding = "utf-8"
bs = BeautifulSoup(html.text, "html.parser")
results = bs.find_all('table',{'log-set-param':'table_view','data-sort':'sortDisabled'})
- 观察爬取的tables,选取最后一个表格作为最终分析对象,遍历内部的tr,td标签,找到每一个div标签对应的text;
show_list = []
trs = results[3].find_all('tr')
for tr in trs:
tds = tr.find_all('td')
temp_list = []
for td in tds:
temp_list.append(td.find('div').text)
show_list.append(temp_list)
fin_table = pd.DataFrame(show_list)
fin_table.drop(fin_table.index[0])
df = fin_table[1:]
arr = df.values
df = pd.DataFrame(arr[1:, 1:], index=arr[1:, 0], columns=arr[0, 1:])
df.index.name = arr[0, 0]
- 将数据分别存储,获得‘东方卫视CSM59城收视.csv’和‘浙江卫视CSM59城收视.csv’;
df_1.to_csv('data\\result\\{}.csv'.format(fin_table.iloc[0,1]))
df_2.to_csv('data\\result\\{}.csv'.format(fin_table.iloc[0,2]))
数据处理
相关函数/对象:
process(data)
这一部分对数据进行的处理:
df = df.replace('\n', ' ', regex=True)
df = df.replace(u"\\[.*?]", "", regex=True)
df = df.replace(u"\xa0", "", regex=True)
- 对中文名属性进行分列处理,得到中文名和角色名两个属性;
df['中文名'] = df['name'].map(lambda x: x.split('饰')[0])
df['角色名'] = df['name'].map(lambda x: x.split('饰')[1])
最后将结果存储为’data/result/result_2.csv’。
数据可视化分析
这一部分使用的仍是pyecharts。
参演人员统计
相关函数/对象:
process.process_list(self)
首先提取data中的中文名属性,考虑到词云统计更加适应演员名单的显示,因此这里仍使用词云进行表示统计结果。对于权重的确认,我们根据爬取的顺序,即百度百科显示的顺序进行赋权,通过不断缩小随机数的范围使得更为重要的演员突出。代码如下:
for name in df:
result[name] = str(random.randint(100, temp))
temp = temp - 10
result = [(a, b) for a, b in result.items()]
最后绘制词云图,存储为"data/htmls/平凡的荣耀参演人员统计.html"
word_cloud = (
WordCloud()
.add("平凡的荣耀", result, word_size_range=[20, 60],
textstyle_opts=opts.TextStyleOpts(font_family="Fantasy"))
.set_global_opts(title_opts=opts.TitleOpts(title="平凡的荣耀参演人员",
title_link="https://baike.baidu.com/item/%E5%B9%B3%E5%87%A1%E7%9A%84%E8%8D%A3%E8%80%80",
subtitle="xhsioi",
subtitle_link="https://xhsioi.github.io/"))
)
可视化结果如下:

可以看到,主演赵又廷、庞瀚辰等人在图表中更为突出,其他配角位于边缘,简洁明了地体现出了演员在剧中角色的分量。
毕业院校统计
相关函数/对象:
process.process_school(self)
首先提取data中的毕业院校属性,对该属性进行筛选,截取其中包含’大学’, ‘学院’, ‘话剧团’, '话剧院’的有效前缀字符串,得到数据后对毕业院校进行计数,汇总得出对应的毕业院校字典。筛选过程如下:
temp = df['毕业院校'].values.tolist()
check = ['大学', '学院', '话剧团', '话剧院']
school_result = []
for ch in check:
school_result = school_result + [str(x).partition(ch)[0] + ch for x in temp if
len(str(x).partition(ch)[0]) != len(str(x))]
将字典转化成list,进行饼状图可视化分析,存储为"data/htmls/毕业院校统计.html",代码如下:
pie = (
Pie().add(
series_name="毕业学校统计",
data_pair=[list(z) for z in temp],
radius=["40%", "80%"]
)
.set_global_opts(
title_opts=opts.TitleOpts(title="演员毕业学校统计",
title_link="https://space.bilibili.com/2018113152/",
subtitle="xhsioi",
subtitle_link="https://xhsioi.github.io/"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="10%", pos_left="2%")
)
.set_series_opts(
label_opts=opts.LabelOpts(formatter="{b}")
)
)
可视化结果如下图所示,鼠标悬停特定区域可以获取对应毕业院校毕业人数:

从演员毕业学校可视化结果可以看出,平凡的荣耀中中央戏剧学院、北京电影学院、上海戏剧学院的人数最多,分别为14,9,4。不仅有国内的大学表演系毕业生,还有一位来自维多利亚的毕业生参与了电视剧的制作。同时,我们看到话剧团或话剧院的毕业生也参与了电视剧的制作,话剧演员的加入让电视剧具有了一丝话剧的趣味。
收视率、收视份额可视化分析
相关函数/对象:
process.process_school(self)
首先分别获取两个卫视的播出日期、收视率、收视份额三项数据,同时完成数据类型转换:
df_1 = pd.read_csv('data/result/东方卫视CSM59城收视.csv')
df_2 = pd.read_csv('data/result/浙江卫视CSM59城收视.csv')
show_time = df_1['播出日期'].astype(str).values.tolist()
watch_rate_1 = df_1['收视率%'].astype(float).values.tolist()
watch_rate_2 = df_2['收视率%'].astype(float).values.tolist()
watch_per_1 = df_1['收视份额%'].astype(float).values.tolist()
watch_per_2 = df_2['收视份额%'].astype(float).values.tolist()
绘制综合收视率、收视份额的组合图,这里使用grid将折线图和柱状图进行整合,将结果存储为"data/htmls/收视数据统计.html",相关代码如下:
bar_1 = (
Bar()
.add_xaxis(show_time)
.add_yaxis(
"东方卫视收视率",
[round(x, 1) for x in watch_rate_1],
yaxis_index=0,
color="#d14a61"
)
.add_yaxis(
"浙江卫视收视率",
[round(x, 1) for x in watch_rate_2],
yaxis_index=0,
color="#5793f3"
)
.extend_axis(
yaxis=opts.AxisOpts(
name="收视份额",
type_="value",
min_=0.0,
max_=12.0,
position="left",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="#675bba")
),
axislabel_opts=opts.LabelOpts(formatter="{value} %")
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="收视率可视化分析", subtitle="xhsioi"),
legend_opts=opts.LegendOpts(pos_left="50%"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
yaxis_opts=opts.AxisOpts(
name="收视率",
min_=0.0,
max_=4.0,
position="right",
offset=80,
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="#5793f3")
),
axislabel_opts=opts.LabelOpts(formatter="{value} %"),
)
)
)
line_1 = (
Line()
.add_xaxis(show_time)
.add_yaxis(
"东方卫视收视份额",
[round(x, 1) for x in watch_per_1],
yaxis_index=1,
color="#2F4DC9",
)
.add_yaxis(
"浙江卫视收视份额",
[round(x, 1) for x in watch_per_2],
yaxis_index=1,
color="#A6CE1B",
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
bar_1.overlap(line_1)
grid = Grid(init_opts=opts.InitOpts(width="1600px"))
grid.add(bar_1, opts.GridOpts(pos_left="15%", pos_right="15%"), is_control_axis_index=True)
可视化结果如下图所示,将鼠标悬停在某一点,显示当前点的坐标以及各个卫视的收视率和收视份额。

通过收视率、收视份额可视化结果可知,各个卫视的收视率、收视份额整体的变化趋势是相近的,两个卫视的收视数据都在9.12和9.27达到了峰值。对于东方卫视,9.12收视率为2.7%、收视份额为9.7%;9.27收视率为3%,收视份额10.7%。对于浙江卫视,9.12收视率为2.1%、收视份额为7.5%;9.27收视率为2.4%,收视份额为8.4%。
对于不同卫视的收视份额以及收视率,从峰值数据来看,东方卫视份额要高于浙江卫视,从整体来看,东方卫视和浙江卫视的数据大致相同。因此我们可以看出每天通过两个卫视观看该电视剧的观众比例大致相同,但从实际的收视份额来看,在剧情迎来转折或者结局时,更多的观众愿意通过东方卫视进行观看。
最后,可以看出收视率变化相较于收视份额变化较为平缓,体现出电视剧前期收视数据逐步升高,中期收视数据较为平稳,后期收视数据突然提高的特点。
收视排名分析
相关函数/对象:
process.process_rank(self)
首先分别获取两个卫视的电视剧收视排行信息,同时完成数据类型转换:
df_1 = pd.read_csv('data/result/浙江卫视CSM59城收视.csv')
df_2 = pd.read_csv('data/result/东方卫视CSM59城收视.csv')
rank_1 = df_1['排名'].astype(str).values.tolist()
rank_2 = df_2['排名'].astype(str).values.tolist()
对排名的数据进行计数,得到排名字典,将字典转为list之后进行排序,东方卫视的排名数据整理代码如下:
results_1 = {}
for rs in rank_1:
results_1[rs] = results_1.get(rs, 0) + 1
temp_1 = [(a, b) for a, b in results_1.items()]
temp_1 = sorted(temp_1, key=(lambda x: x[0]))
绘制两个电视台的平凡的荣耀收视排名饼状图,将文件存储为"data/htmls/收视排名分析.html":
pie = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
.add(
"浙江卫视收视排名",
[list(z) for z in temp_1],
center=["20%", "30%"],
radius=[40, 80],
label_opts=opts.LabelOpts(formatter="浙江", position="center")
)
.add(
"东方卫视收视排名",
[list(z) for z in temp_2],
center=["55%", "30%"],
radius=[40, 80],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="收视排名分析", subtitle="xhsioi"),
legend_opts=opts.LegendOpts(
type_="scroll",
pos_top="20%",
pos_left="80%",
orient="vertical"
)
)
.set_series_opts(
label_opts=opts.LabelOpts(formatter="第{b}名:{d}%")
)
)
可视化结果如下,鼠标悬停于制定区域可以获得对应电视台信息以及当前排名对应的天数:
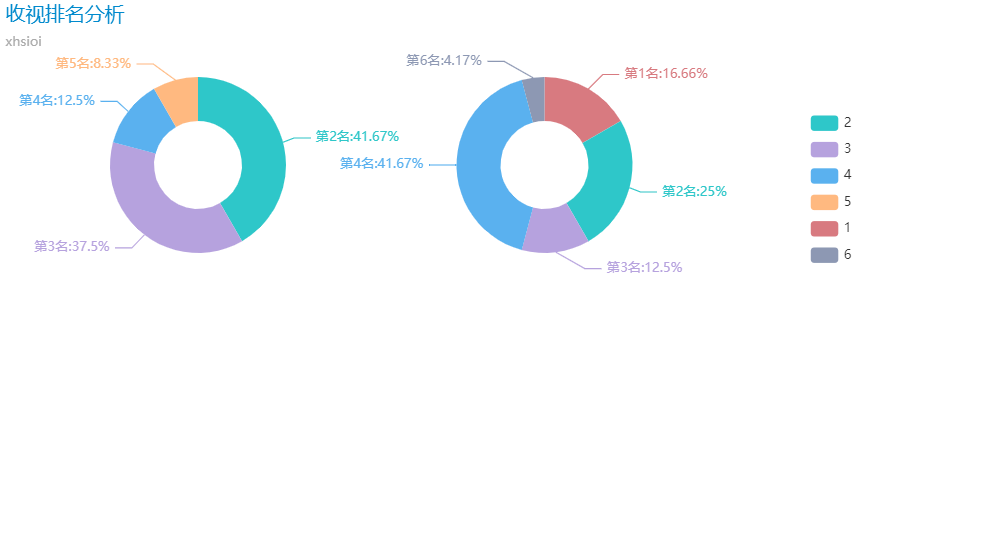
从上图可以看出,该电视剧在浙江卫视41.67%的播出时间内收视第二名;在东方卫视41.67%的播出时间内收视第四名。此外,浙江卫视在接近75%的播出时间内斗占据着浙江卫视的收视前三名,与之形成对比的东方卫视只有接近一半的播出时间平凡的荣耀占据收视前三名。
可视化的所有结果汇总于"合并.html"。