作业一实验报告
重要的库
from random import random
import pandas as pd
import numpy as np
import get_data as crawlers
from itertools import chain
from pyecharts.globals import SymbolType
from pyecharts.charts import Bar
from pyecharts.charts import Pie
from pyecharts.charts import Map
from pyecharts.charts import Line, Grid, Liquid, WordCloud
from pyecharts.options.global_options import ThemeType
from pyecharts.commons.utils import JsCode
from pyecharts import options as opts
import random
数据爬取
根据题干要求,爬取百度百科中乘风破浪的姐姐第二季所有嘉宾的词条信息以及对应外链的相关信息。整体的步骤如下:
- 获取参演嘉宾的html代码;
- 遍历每个参演嘉宾对应的html代码,保存每个嘉宾的基本信息,形成嘉宾名单;
- 根据保存的外链,爬取每个嘉宾对应百度百科的词条基本信息;
- 进行数据预处理,整合所有嘉宾的数据;
获取对应的html
这一部分使用的BeautifulSoup与requests中的库函数进行数据获取。首先,我们对整个页面中有table标签且属性为"log-set-param": "table_view"的html代码进行爬取,过程如下:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.99 Safari/537.36 '
}
html = requests.get(url, headers=headers)
html.encoding = "utf-8"
bs = BeautifulSoup(html.text, "html.parser")
results = []
tables = bs.find_all('table', {"log-set-param": "table_view"})
然后对tables进行遍历,找到titles中所需的table,即"竞演嘉宾",“助阵嘉宾”,“制作团”:
for table in tables:
table_titles = table.find_previous('div').find_all('h3')
for table_title in table_titles:
temp = [t.extract() for t in table_title('span')]
if table_title.text in titles:
results.append(table)
此时的results包含所求的嘉宾名单html代码。
获取所有嘉宾名单以及信息
只是获取对应的table是不够的,因此需要进一步处理。根据三个table中嘉宾数据位于的标签不同,这一部分将会分成两部分:
- “竞演嘉宾”, "助阵嘉宾"数据提取;
- “制作团”数据提取;
对于利用tr标签提取的数据,遍历表格内的每一个tr标签,取每个tr标签中的第一个td标签即可:
相关代码如下:
def getData_in_tr(tables, titles):
temp_result = []
for table in tables:
trs = table.find_all('tr')
for tr in trs[1:]:
tds = tr.find_all('td')
if tds[0].text not in titles:
temp_result.append(tds[0])
return calculate(temp_result)
对于利用td标签提取的数据,遍历并存储每一个td标签:
相关代码如下:
def getData_in_td(tables):
temp_result = []
for table in tables:
trs = table.find_all('tr')
for tr in trs[:-1]: #去除表格最后一行的注释
tds = tr.find_all('td')
for td in tds:
temp_result.append(td)
return calculate(temp_result)
接着根据获取到的数据,爬取对应嘉宾相关链接中的信息,这里爬取的是每个嘉宾基本信息中表格的全部信息,步骤如下:
- 将获得的数据中href对应的链接提取出来;
- 爬取div标签,属性为’class’: 'basic-info J-basic-info cmn-clearfix’的html代码;
- 对内部的dt,dd标签进行遍历,其中dt.text作为key,dd.text作为value,形成字典;
- 在遍历过程中,保存对应链接中的图片留为备用;
- 将字典数据进行汇总,转化为DataFrame,获得明星名单;
calculate(temp_result)函数的相关代码如下:
stars = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.99 Safari/537.36 '
}
for tr in temp_result:
star = {}
star["link"] = 'https://baike.baidu.com' + tr.find('a').get('href')
html = requests.get(star["link"], headers=headers)
html.encoding = "utf-8"
bs = BeautifulSoup(html.text, "html.parser")
result = bs.find('div', {'class': 'basic-info J-basic-info cmn-clearfix'})
dt = result.find_all('dt')
dd = result.find_all('dd')
item = 0
for t in dt:
index = "".join(t.text.split())
star[index] = dd[item].text.strip()
item += 1
stars.append(star)
get_pic(star['link'], star['中文名'], bs)
result_answer = pd.DataFrame(stars)
return result_answer
获取嘉宾图片
根据嘉宾的相关链接,爬取img标签属性为{‘alt’: name}或者{‘class’: ‘picture’}的src属性,调用pic_check函数进行链接筛选,得到图片链接,将图片保存到指定文件夹。
def pic_check(pics):
urls = []
for pic in pics:
url = pic.get('src')
if url is None:
continue
if url[:6] == 'https:':
urls.append(url)
print(url)
return urls
数据处理
数据处理部分较为简单,上一部分将数据转为DataFrame格式进行保存,因此只需要构建一个process对象,调用pre_processing()函数进行处理。
对于pre_processing()函数的内部实现,主要是实现了以下功能:
- 去除数据中多余符号;
- 修改columns中存在的格式问题;
最后,将得到的数据保存为’work/data/result_1.csv’。
数据可视化分析
本次大作业使用的可视化库为pyecharts,Echarts是一个由百度开源的商业级数据图表,它是一个纯JavaScript的图表库,可以为用户提供直观生动,可交互,可高度个性化定制的数据可视化图表,赋予了用户对数据进行挖掘整合的能力,因此,我们可以定义:pyecharts库是一个用于生成 Echarts 图表的类库。
pyecharts及相关库安装
# 在pycharm的终端中进行安装
pip install pyecharts
pip install echarts-china-provinces-pypkg
pip install snapshot-selenium -i http://pypi.douban.com/simple --tru
sted-host pypi.douban.com
嘉宾名单词云化展示
对应函数:process_list(self)
首先提取data中的’中文名‘属性,进行数据的初步处理,想要利用词云进行可视化,利用随机数确定每一位嘉宾的权重。
data = self.data
result = {}
df = data['中文名']
for name in df:
result[name] = str(random.randint(10, 1000))
result = [(a, b) for a, b in result.items()]
进行词云绘图,将结果保存为"work/htmls/嘉宾名单.html":
word_cloud = (
WordCloud(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add("嘉宾展示", data_pair=result, word_size_range=[10, 70])
.set_global_opts(
title_opts=opts.TitleOpts(
title="嘉宾名单", subtitle="xhsioi", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
)
)
)
最后得到如下可视化结果,鼠标悬停于对应姓名可以显示其对应的权重,这里只是部分名单显示,调节字体大小参数从而获得整体的名单。

嘉宾职业统计
对应函数:process_jobs(self)
首先提取data中的’职业‘属性,利用正则表达式去除各个职业之间的分隔符以及nan元素,同时将所有的职业汇总为list,对list中的职业进行计数,得到关于嘉宾职业的计数。
data = self.data
data['职业'].replace(' ', '', regex=True)
df = data['职业'].str.split('、|,', expand=True)
jobs = list(set(chain.from_iterable(df.drop_duplicates().values.tolist())))
jobs = list(filter(None, jobs))
jobs.remove(np.nan)
works = data['职业'].astype(str).to_list()
cal = np.zeros(len(jobs))
for i in works:
for j in range(0, len(jobs)):
if jobs[j] in i:
cal[j] = cal[j] + 1
绘制饼状图,将结果保存为"work/htmls/嘉宾职业统计.html":
pie = (
Pie().add('', [list(z) for z in zip(jobs, cal)], radius=["30%", "65%"])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
得到如下的可视化结果,鼠标悬停于对应模块,可以获取当前职业的人数:
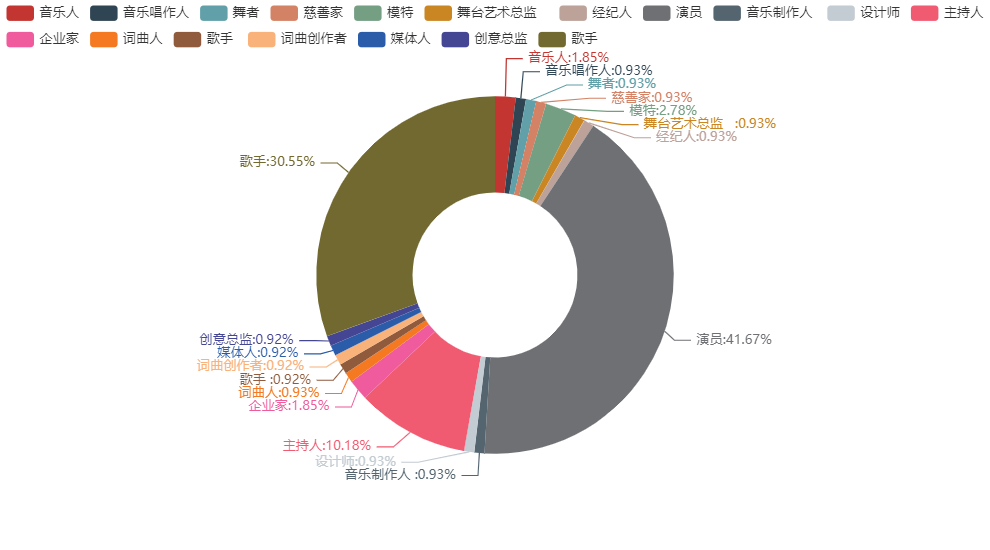
从职业分布可以看出,职业是演员、歌手以及主持人的嘉宾占比较高,分别占比41.67%,30.55%,10.18%;职业是创意总监、媒体人、词曲创作者的嘉宾占比最低,均为0.92%。演员、歌手以及主持人往往被大众所熟知,制作方抓住了这一点,从选择综艺角色这一方面下了功夫。从职业的角度分析,不仅体现出制作组选角的策略,同时也暗含了大众对于明星的印象,即相较于其他明星,作为演员、歌手的姐姐们更加外向、自信、充满激情和干劲,更加适合这种综艺节目。
嘉宾星座统计
对应函数:process_constellation(self)
首先提取data中的’星座‘属性,经过处理后得到星座list,对星座进行计数得到对应字典。
constellations = list(set(data['星座'].astype(str).drop_duplicates().values.tolist()))
constellations = list(filter(None, constellations))
constellations.remove('nan')
constellations = [x for x in constellations if len(x) == 3]
temps = data['星座'].astype(str).to_list()
绘制柱状图,将结果保存为"work/htmls/嘉宾星座统计.html":
bar = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)).add_xaxis(constellations).add_yaxis("数量统计", cal)
.set_global_opts(
title_opts=opts.TitleOpts(title="嘉宾星座统计", subtitle="xhsioi"),
legend_opts=opts.LegendOpts(pos_left='right')
)
)
得到如下的可视化结果:

从嘉宾星座统计可以看出,白羊座人数最多,其次是金牛座、天蝎座,在节目中,她们体现出了特有的强烈的好奇心、坚强的意志力,不服输和冒险犯难、创新求变的精神,这与他们星座的性格特点息息相关。同时我们可以看到,射手座和双鱼座的嘉宾较少,正好照应了综艺的主题——乘风破浪的姐姐,双鱼座和射手座相较于其他星座更容易受环境影响,缺乏理性,多愁善感,优容寡断,很明显是不适合这档综艺的。这里再一次体现了节目组选角的巧妙:拉入较多的乐观向上、好奇心满满的姐姐们,带动其他少数姐姐们一同乘风破浪。
嘉宾出生地统计
对应函数:process_born(self)
首先提取data中的出生地信息,构建包含全国省市的check_areas,进行出生地计数:
check_areas = ['河北', '山西', '辽宁', '吉林', '黑龙江', '江苏', '浙江', '安徽', '福建', '江西', '山东', '河南', '湖北', '湖南', '广东', '海南',
'四川', '贵州', '云南', '陕西', '甘肃', '青海', '台湾',
'内蒙古', '广西', '西藏', '宁夏', '新疆',
'北京', '天津', '上海', '重庆',
'香港', '澳门',
'其他']
dff = data['出生地'].values.tolist()
flag = True
for i in dff:
for j in range(0, len(check_areas)):
if check_areas[j] in str(i):
cal[j] = cal[j] + 1
flag = False
if flag:
flag = True
cal[len(check_areas) - 1] = cal[len(check_areas) - 1] + 1
cal = [str(x) for x in cal]
基于中国地图绘制出生地热力图,保存为"work/htmls/嘉宾出生地统计.html",鼠标悬停在某一区域会显示对应的人数,同时可以调节左侧滑块:
mapp = (
Map().add("出生地", [list(z) for z in zip(check_areas, cal)], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="嘉宾出生地分布", subtitle="xhsioi"),
visualmap_opts=opts.VisualMapOpts(max_=6)
)
)
可视化结果如下:
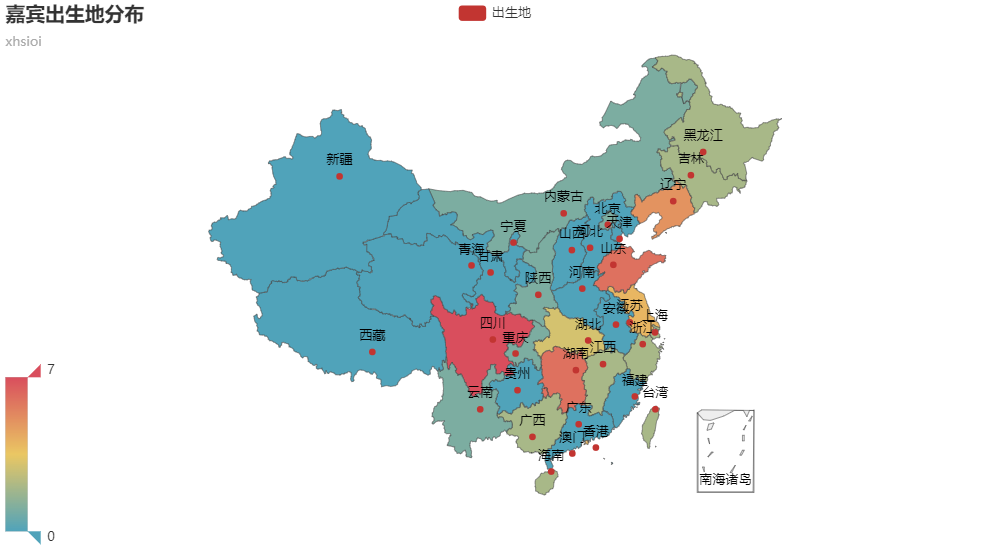
从出生地统计可以发现,嘉宾大多数来自中国的中东部地区,其中四川、湖南、山东、辽宁的嘉宾最多,在这四个省中,四川省的嘉宾数量一枝独秀,达到最多的7个人,其次就是湖南。可以看出,嘉宾中的湘妹子、川妹子的数量是最多的。此外,西部的新疆、西藏、青海、甘肃的嘉宾最少,都为0,这一部分的空缺制作组可以在未来的节目中补充完整。
嘉宾年龄分布
对应函数:process_age(self)
首先提取data中的出生日期数据,然后筛选出不满足的数据,最后得到嘉宾的出生年份,根据出生年份得到嘉宾年龄,从而进行统计,得到年龄统计数据:
df['年'] = df['出生日期'].map(lambda x: x.split('年')[0])
years = df['年'].values.tolist()
years = [x for x in years if len(x) == 4]
ages = [2022 - int(x) for x in years]
result = {}
for i in ages:
result[i] = result.get(i, 0) + 1
temp = [[a, b] for a, b in result.items()]
temp = sorted(temp, key=(lambda x: x[0]))
ages = [str(x[0]) for x in temp]
number = [str(x[1]) for x in temp]
绘制曲线图,得到如下结果:
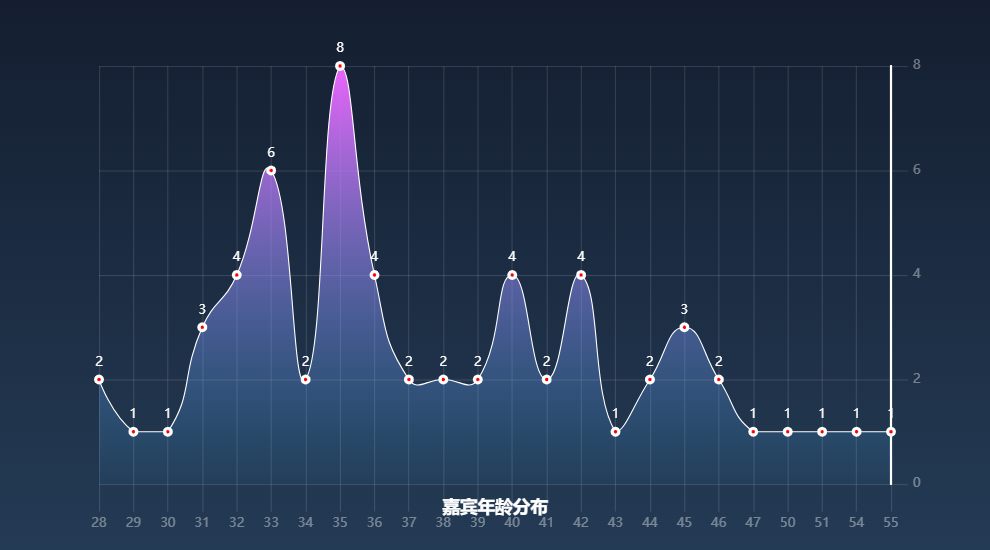
整体上来看,大多数嘉宾的年龄都是30+,大多数集中于33-37岁之间,35岁的嘉宾数量最多,达到了8人;29-30岁和47-55岁的嘉宾数量最少。以上的分析说明大多数的嘉宾正值壮年,充满活力,成熟且有魅力,符合节目主题。当然,40岁以上的嘉宾也有很多,占所有嘉宾的30%左右,刨除制作图案成员的影响,我们可以看出姐姐们整体上看都处于黄金年龄,充满知性和感性。
嘉宾血型统计
对应函数:process_blood(self)
首先提取data中的血型信息,清洗之后对血型进行计数:
dff = df['血型'].values.tolist()
dff = [x.strip() for x in dff if x != 'nan']
result = {}
for i in dff:
result[i] = result.get(i, 0) + 1
temp = [[a, b] for a, b in result.items()]
blood_type = [x[0] for x in temp]
number = [x[1] for x in temp]
blood_percent = [round(x / sum(number), 4) for x in number]
绘制对应血型的水球图:


从血型水球图可以看出,O型血的嘉宾数量最多,AB型血的数量最少。O型血的人更加富有干劲,在办事的时候会全力以赴,越是困难得到状况,他会越感觉富有挑战性;与之形成对比的AB型血虽然显的更为成熟,但往往和其他人的距离感和疏离感特别强。因此,选择更为热情奔放的O型血嘉宾,不仅照应了乘风破浪的主题,而且提高了节目的趣味性。
可视化结果汇总于"合并.html"