CVPR2020 Counterfactual Samples Synthesizing for Robust VQA Note
[TOC]
相关背景
Question Only Model(RUBi)
https://blog.csdn.net/weixin_42305378/article/details/105809513
常规的vqa处理中使用很多统计规律,计算答案出现的次数和问题中某些模态之间的统计规律。在本文中 question-only模型用于和传统的vqa计算进行比较,突出这种单模态模型存在的问题,提出了RUBi模型进行改进,主要改进就是在整体vqa顶层添加了一个问题模型,掩盖答案之后进行生成,从而减少正例的损失,增加反例的损失。
这就是本文提到的使用问题模型对模型进行正则化的过程,存在视觉解释性不足以及问题敏感性的缺点。
LMH Model
https://blog.csdn.net/bxg1065283526/article/details/106163357
常规vqa模型注重特定的关键词,不注重上下文关系问题,这篇文章首先训练了仅基于数据集偏差进行预测的朴素模型,然后将训练之后的模型和朴素模型进行拟合,生成鲁棒性更高的模型,该方法也是着重于对vqa的偏置项进行处理,提升反例对应的偏置,降低正例对应的偏置,相关公式如下:

其中g是一个学习的函数,bi为偏置项,具体的推导过程如下图所示:

VQA Bias
一般指的语言偏置,他会使得模型在回答问题时依赖于问题和答案之间的表面相关性。需要注意的是,这里的偏置区别于归纳偏置,对语言的先验都是存在坏的语言偏置和好的语言上下文。
- 坏的语言偏置:对一个大概率问题不假思索地判断,体现特定的规则。
- 好的语言上下文:question的上下文可能存在一些特定规则辅助预测。
VQA CP
在文章中提到了VQA-CP的工作提升了模型的鲁棒性,但是在VQA-CP数据集上所做的诸多工作,竟然在一个鲁棒性指标RAD上完全输给了未经过Bias抑制处理的VQA模型。但是从整体上看,抑制偏置的前景是光明的。
Grad-CAM(Class Activation Map)
Gram-CAM发生在卷积的最后一层,绘制热力图,对应给定的类别,了解网络到底关注哪些区域,可视化哪些部分对预测结果的贡献最大。

其计算如下图所示,A代表网络最后一层卷积的输出大小,w代表全联接层的权重大小,c为分类的类别。
FVQA
涉及外部知识的VQA任务,利用知识库KB中的某条fact进行计算求解
the existing state-of-the-art visualexplainable model SCR
论文链接:https://arxiv.org/abs/1905.09998
项目地址:https://github.com/jialinwu17/Self_Critical_VQA
还是针对训练数据关注于表面文字的统计规律,因此提出了自我批判的训练目标。这里作者认为模型能够选出更有影响力的图像区域,其取决因素在于人类视觉或文本、QA中的重要词两个因素。
学会了正确的判断方法进行预测时,依旧出现关注某些部分人类标注的特殊区域问题,因此引入自我批评,即出现错误答案惩罚该区域关注度,关键端到端可训练的自我批评方法,实现的方法如下:
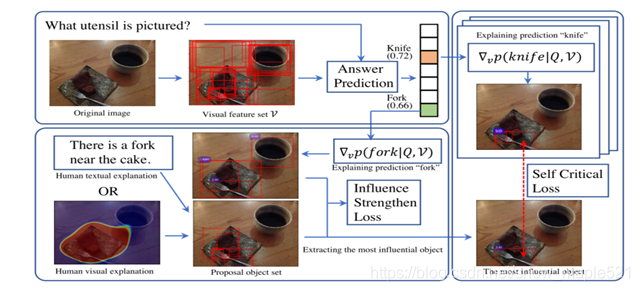
Consensus Score
一种聚类的指标,衡量聚类结果的稳定性。
Abstract
视觉问答的发展过度依赖训练集表面的语言相关性,无法推广至具有不同QA分布的测试集,特指Question Only模型,因此从视觉可解释性和问题敏感性两个方面进行训练,给出了CSS训练方案,通过屏蔽图像中的关键对象或问题中的单词,分配不同的基本真值答案,生成大量反事实训练样本,在后续构建的LMH模型中性能显著提高。
- 视觉解释:正确的答案+正确的对象识别;
- 问题敏感能力:问题内部对象替换后预测答案的变化;
Introduction
纵然vqa有了如VQA v1和VQAv2这类的数据集,但是由于图片标注必然存在误差,因此传统模型更加依赖于表面的语言。并非所有数据集都存在相同分布,新给出的VQA-CP数据集注意到这个问题,能够更全面地分析模型的准确性。总而言之,这些方法要么基于对抗,最小化损失,减少正向偏置,增加反向偏置;要么基于融合,研究如何将两个模型的结果进行合并。
本文推出了基于对抗的CSS训练方案,分为V-CSS,即对原始图像掩盖,合成反事实图像,构建新的VQ对;Q-CSS,掩盖真实关键词,构建新的VQ对。加入以上两种VQ对,使模型被迫专注于关键的对象和单词。广泛的消融实验证明了模型能力。
- 语言偏差解决办法:平衡数据集或者设计模型减小偏差。
- 视觉解释能力:传统的GradCAM虽然能够进行热力图的绘制,但是需要人工标注数据、同时不是端到端的模型(原始的输入,通过模型直接获得结果)。
- 问题敏感性:研究的工作较少,相关的研究更加注重更换措辞,并没有关注关键词替换的问题。
- 反事实训练样本生成。
Approach
生成特殊的VQ分布,构建自顶向下的模型,合成反事实样本;
Preliminaries
使用问题编码器构建V和Q两个集合,代表不同对象的特征以及不同单词的特征,然后使用fvqa预测答案的分布:
Pvqa(a∣I,Q)=fvqa(V,Q)
这里的fvqa是用了注意力机制以及交叉熵损失,关注于融合模型,放弃结果较差的对抗模型,接下来引入纯问题模型fq,即:
Pq(a∣Q)=fq(Q)
然后将两个结果融合得到分布: $ \widehat {P}_ {vqa} $ (a|I,Q)=M( $ P_ {vqa} $ (a|I,Q), $ P_ {q} $ (a|Q)).
Counterfactual Samples Synthesizing (CSS)
三个主要步骤,即分别对原始样本、V-CSS以及Q-CSS,其中后两步的实现方法如下图所示

需要注意的是,对应的阈值需要根据不同的模型进行更改,即:
V-CSS
初始对象选择:使用SpaCy为question分配磁性标注,提取nouns,计算对象类别和GloVe嵌入结果的余弦相似度,获得最小对象集。
对象局部贡献计算:改进的Grad-CAM计算,公式如下:
s(a, $ v_ {i} $ )=S( $ P_ {vqa} $ (a), $ v_ {i} $ ):= $ (V_ {v_ {i}}P_ {vqa}(a))^ {T} $
关键对象选择:选择前k个对象作为关键对象集,k满足最小数(即softmax计算贡献度结果),需要注意的事本文阈值设置为0.65。
动态答案分配:生成反例,通过正例带入模型计算结果分布,然后取概率最高的几个作为答案称为集合a+,其他的作为a-,返回a-,这样就获得了反例的a集合。
Q-CSS
和Q-CSS相似,单词本地贡献计算、关键单词选择(Q-代表关键词遮盖的句子,Q+代表遮盖其他的句子)和动态答案分配
Experiments
Hyperparameters of V-CSS and Q-CSS
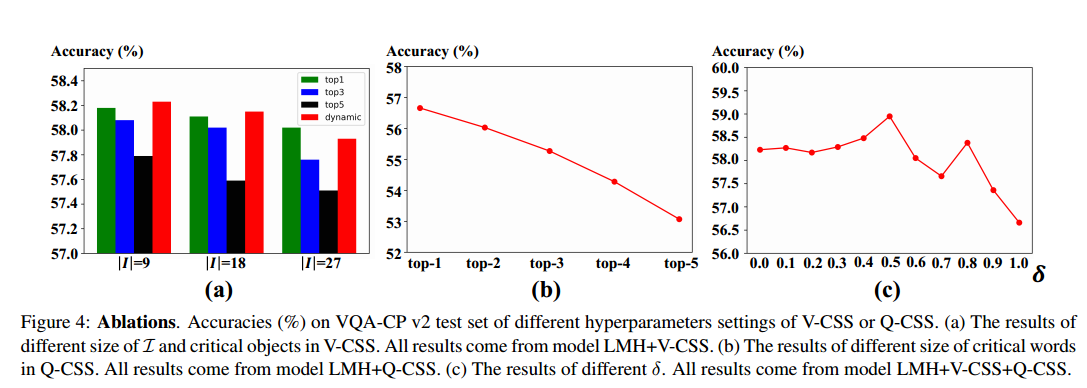
基于LMH模型上的消融实验,结果如下:
消融实验的结果:
- 随着I 的增大,模型的性能逐渐降低;
- V-CSS关键对象的大小维持在一定的水平,动态k达到了最佳性能。
- Q-CSS关键对象的大小,从结果中可以发现只进行一次替换就能达到最佳性能。
- 当sigma为0.5时,准确率最高,效果最好;
Architecture Agnostic
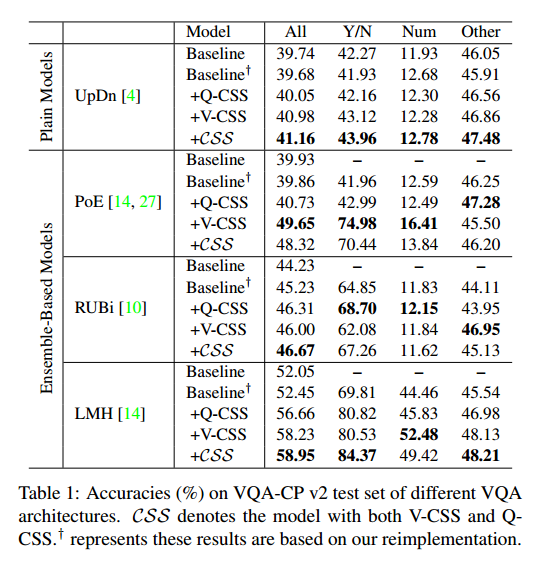
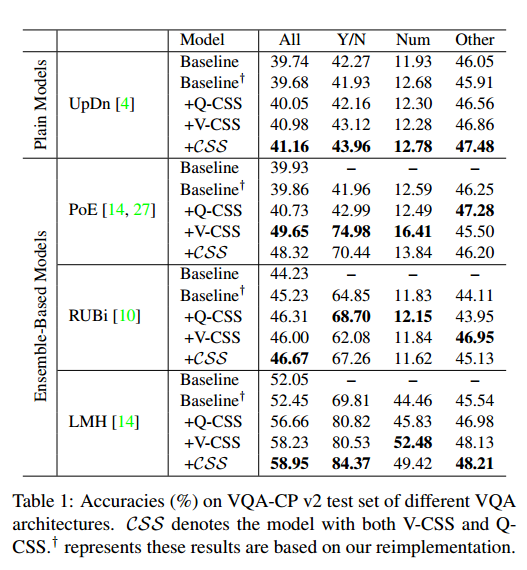
本次实验应用了UpDn、PoE、RUBi、LMH四种模型进行集成,分别计算了不同VQA架构的VQA-CP v2的准确度,均有显著的提升,在基于集成的模型中更为显著
Comparisons with State-of-the-Arts
LMH-CSS,在这两个数据集上分别和最先进的模型比较,即AReg,MuRel、GRL、RUBi等多个模型,进一步降低了语言的偏置作用。
LMH-CSS和VQA-CP v1最新模型对比,相较于baseline有了一定的提升。
Improving Visual-Explainable Ability
研究两个问题,是否能并入集成框架、实现了怎样的提升。
使用SCR+LMH对比CSS+LMH,可视化可解释的模型不能很容易融入到基于集成的框架中,CSS可以提高一定的性能。
将计算得到的SIM值作为为标签,得到度量平均值重要性的新指标,即最高前k个对象的平均SIM分数,从而证明视觉解释能力的提升。
Improving Question-Sensitive Ability
重点研究CSS对模型鲁棒性和语言敏感性的影响,鲁棒性通过CS(k)等参数确定。语言敏感性部分删除了Q中的部分关键词构建新样本,计算置信度。