MMSegmentation语义分割全流程
环境安装
在这一部分,我首先安装配置了MMSegmentation,利用colab平台进行搭建,基本的信息如下:
这里使用的GPU为colab给出的基础款,即Tesla T4。
在之后的过程中,我在设置Matplotlib中文字体时出现了问题,即无法正常显示中文的情况:
搜索得知,colab的虚拟机ubuntu的操作系统没有支持中文的字体,matplotlib配置文件没有支持中文的字体。在matplotlib文件夹中添加tff文件后重新导入依旧存在这个问题,因此直接在代码中引用:
import matplotlib.pyplot as plt
import matplotlib as mpl
zhfont = mpl.font_manager.FontProperties(fname='/usr/share/fonts/truetype/liberation/simhei.ttf')
plt.rcParams['axes.unicode_minus'] = False
然后在绘制的过程中引用即可:
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25, fontproperties=zhfont)
plt.xlabel('X轴', fontsize=15, fontproperties=zhfont)
plt.ylabel('Y轴', fontsize=15, fontproperties=zhfont)
plt.show()
OpenMMLab简述
OpenMMLab作为一个有广泛影响力的人工智能计算机视觉开原算法体系,涉及到图像识别分类、目标检测等多个领域,可以用于开发各种项目,是各类论文的集大成之作。常见算法库有目标检测算法库(MMDetection、MMYOLO)、文字检测识别算法库(MMOCR)、3D目标检测算法库、旋转目标检测算法库(MMRote)、图像分割算法库(MMSegmentation)、图像分类+预训练+多模态算法库(MMPretrain)、高精度姿态估计算法RTMPose等等。之前对视觉问答相关论文进行复现时,出现了baseline准确度较低的情况,我想可以基于MMPretrain对源代码进行修改,提升反事实样本数据的生成效果。
MMYOLO:轻松获得不同版本YOLO在同一个数据集上的跑分;
MMOCR:文本检测、文本识别和关键信息提取;
首先发现之前的环境没有搭载在google drive上,因此今天重新配了一遍。首先是利用Segformer算法实现在Cityscpaes数据集上的预训练,效果如下图:

这里由于是第一次接触Segformer算法,因此进行了较为深入的了解。SegFormer由两部分组成,即一个拥有多头注意力的Transformer encoder,以及一个由多层感知机构成的decoder。
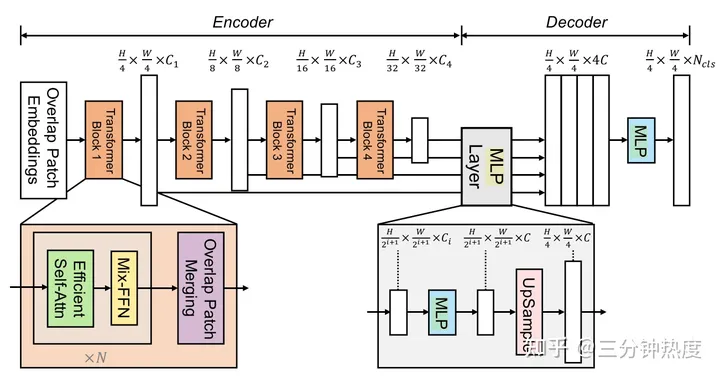
从图中可以看到,encoder是由连续的多个transformer构成,每个transformer模块中都部署了多头注意力模块、归一层和混合前馈神经网络层。
- 分层特征表示:生成一系列不同分辨率大小的特征,即将N x N x 3的patch,转化为1 x 1 x c的向量,使用Patch merging的方法。
- 多头注意力机制:添加了缩放因子R,降低每个注意力模块的计算复杂度。
- 混合前缀神经网络:语义分割任务对于位置编码是不必要的,仅仅通过3x3的卷积就足以动态表达patch间的位置关系。
然后是轻量的decoder,之所以能够构建如此简单的解码器,就是在之前的分层transformer结构接收域更加广泛。论文链接:https://arxiv.org/abs/2105.15203 后续再对文章进行精读和复现,感觉其中的缩放因子的加入过于唐突,应该进一步了解一下。
预训练语义分割模型预测
由于这一部分使用的算法和上述单张图像相同,因此不再赘述。需要注意的是API效果更好,训练更快。下面是我对我拍摄的一组视频进行训练。

显示的结果不是很好,如下图所示。这里推测是因为出现物体较多,以及光源的问题。在我拍摄的视频中光线的分布并不均匀,相较于教程给出的视频噪音过多,恰好从侧面指出了预训练模型的问题,待与之后的模型进行对比后再进行深入研究。

构建分割数据集
这里不再赘述,整体数据分为训练集和验证集,分文件存储图片和标注。

可视化数据结果
这里主要讲如何绘图和着色,以及批量可视化结果,不再赘述。

语义分割算法介绍
这一部分对七种网络的配置文件进行了介绍,主要讲的是相关配置文件的安装,这里深入地学习一下各种算法实现的机理。
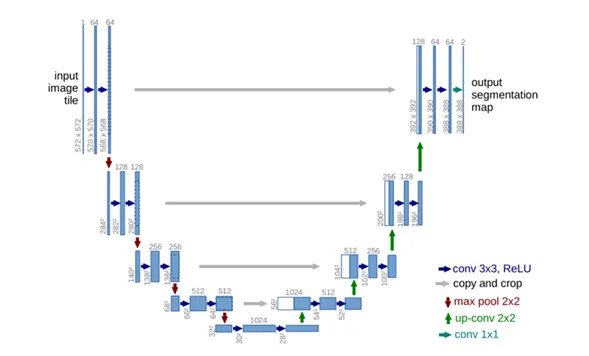
UNet
论文链接:https://paperswithcode.com/method/u-net
提出背景:对于医学图像的处理中,需要对每一个像素进行标注,但是无法获得数钱个训练图像,因此基于FCN进行了数据增强操作,提出了一种U型的网络结构可以同时获取上下文的信息。
组成:下采样(特征提取)、上采样和跳跃连接。其中红色箭头代表最大池化操作,蓝色箭头代表卷积操作。在上采样中保存了大量的通道,保证更高的分辨率。此外还使用了 Overlap-tile策略补全输入图像上下信息。
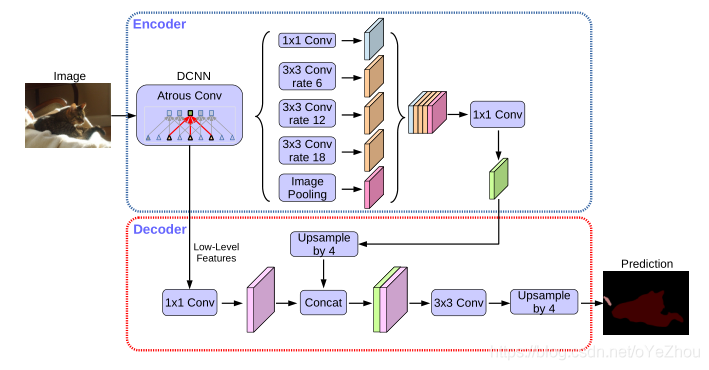
DeepLabV3+
论文链接:https://arxiv.org/pdf/1802.02611.pdf
结构:十分明显的Decoder和Encoder结构
Encoder
包括backbone以及ASPP(空洞卷积层)
其中backbone有两种网络结构:将layer4改为空洞卷积的Resnet系列、改进的Xception。从backbone出来的feature map分两部分:一部分是最后一层卷积输出的feature maps,另一部分是中间的低级特征的feature maps;backbone输出的第一部分送入ASPP模块,第二部分则送入Decoder模块。
ASPP模块接受backbone的第一部分输出作为输入,使用了四种不同膨胀率的空洞卷积块(包括卷积、BN、激活层)和一个全局平均池化块(包括池化、卷积、BN、激活层)得到一共五组feature maps,将其concat起来之后,经过一个1*1卷积块(包括卷积、BN、激活、dropout层),最后送入Decoder模块。
Decoder
在Decoder部分,接收来自backbone中间层的低级feature maps和来自ASPP模块的输出作为输入。
首先,对低级feature maps使用1*1卷积进行通道降维,从256降到48(之所以需要降采样到48,是因为太多的通道会掩盖ASPP输出的feature maps的重要性,且实验验证48最佳);
然后,对来自ASPP的feature maps进行插值上采样,得到与低级featuremaps尺寸相同的feature maps;
接着,将通道降维的低级feature maps和线性插值上采样得到的feature maps使用concat拼接起来,并送入一组3*3卷积块进行处理;
最后,再次进行线性插值上采样,得到与原图分辨率大小一样的预测图。
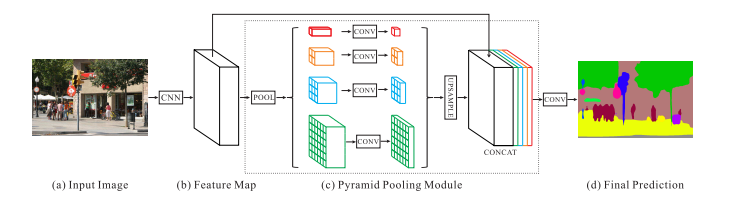
PSPNet
论文链接:https://arxiv.org/abs/1612.01105
提出金字塔池化模块
结合多尺寸信息:SPP(AVE效果优于MAX)
上采样:双线性插值
Tricks:修改Resnet-101 为 ResNet-103、辅助 loss
训练语义分割模型
由于这里使用的显卡太拉,即T4,性能上比较差,因此减少训练的次数为5000,训练过程如下图所示:

可视化训练结果
首先是对训练损失函数的各项数值统计。
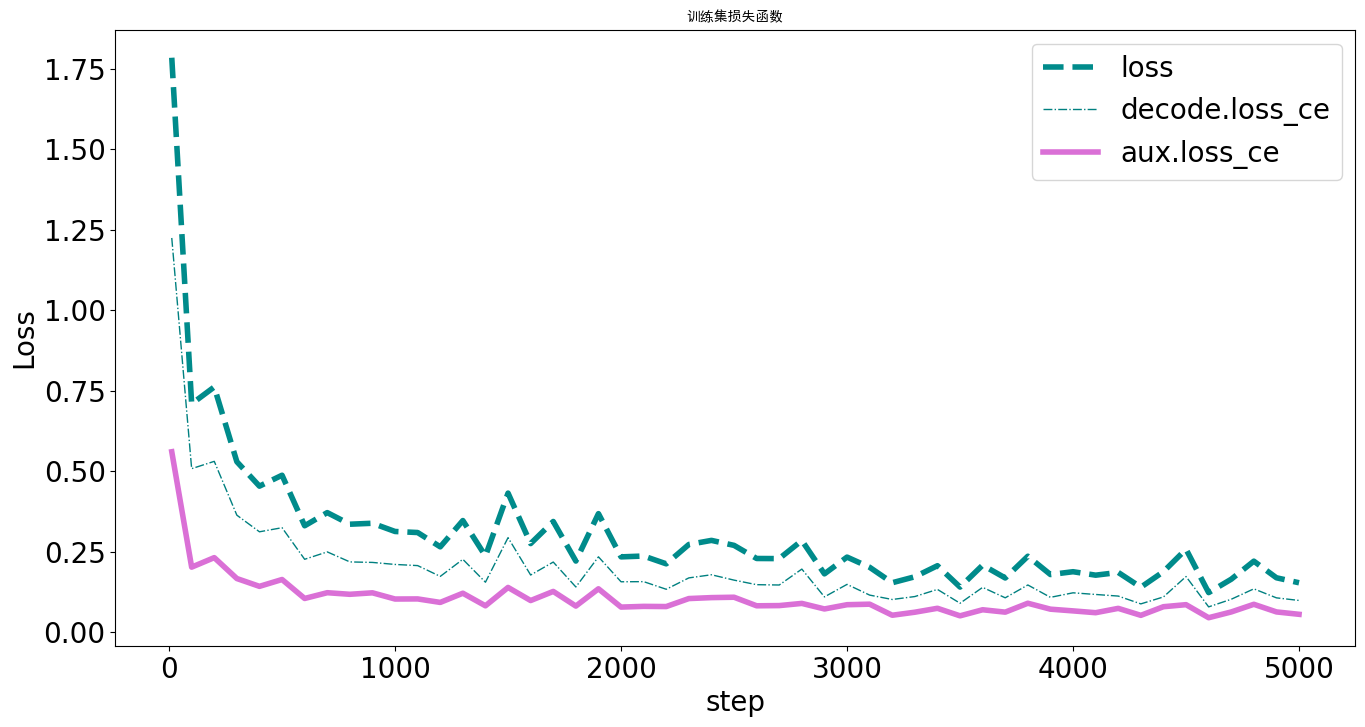
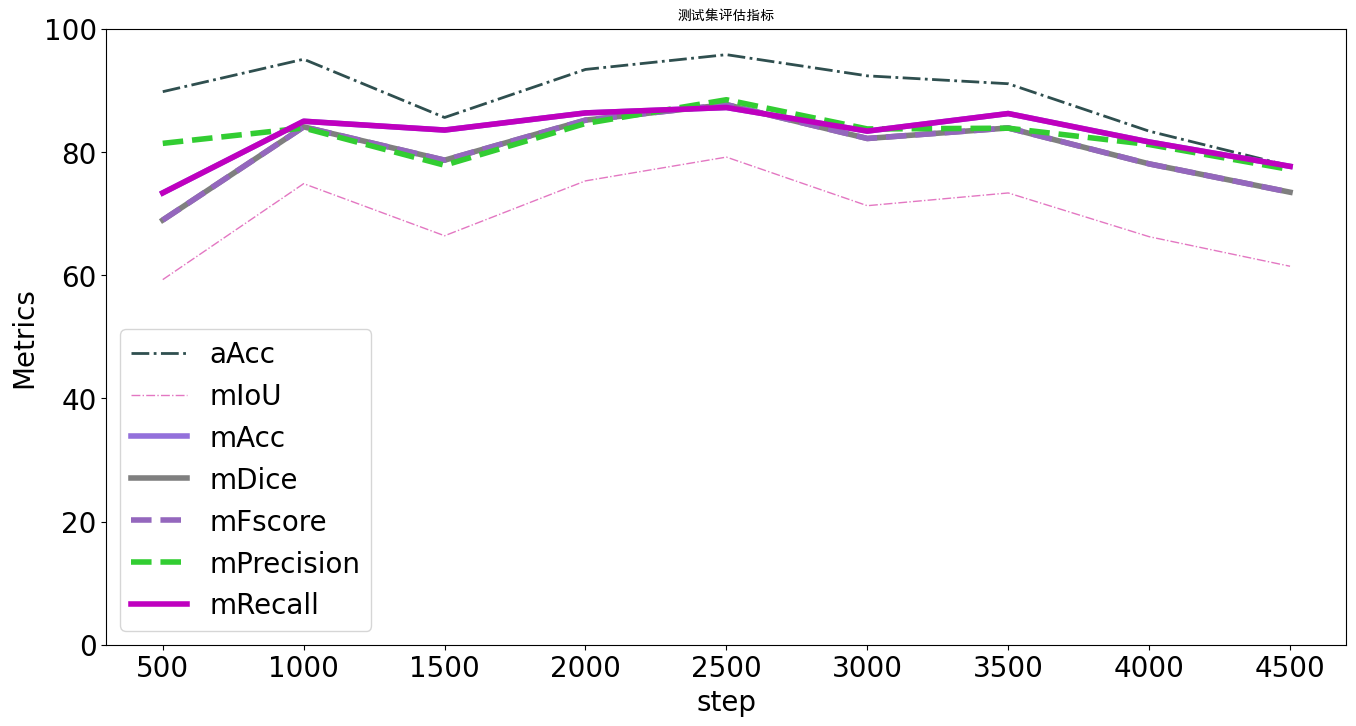
可以看到,在第1000次训练结束之后就已经产生了收敛的趋势,在4000-5000次训练部分趋于稳定状态。对比教程中的图像发现基本符合。然后是对测试集评估指标的统计,明显看出其中的趋势,说明模型的训练结果较好。
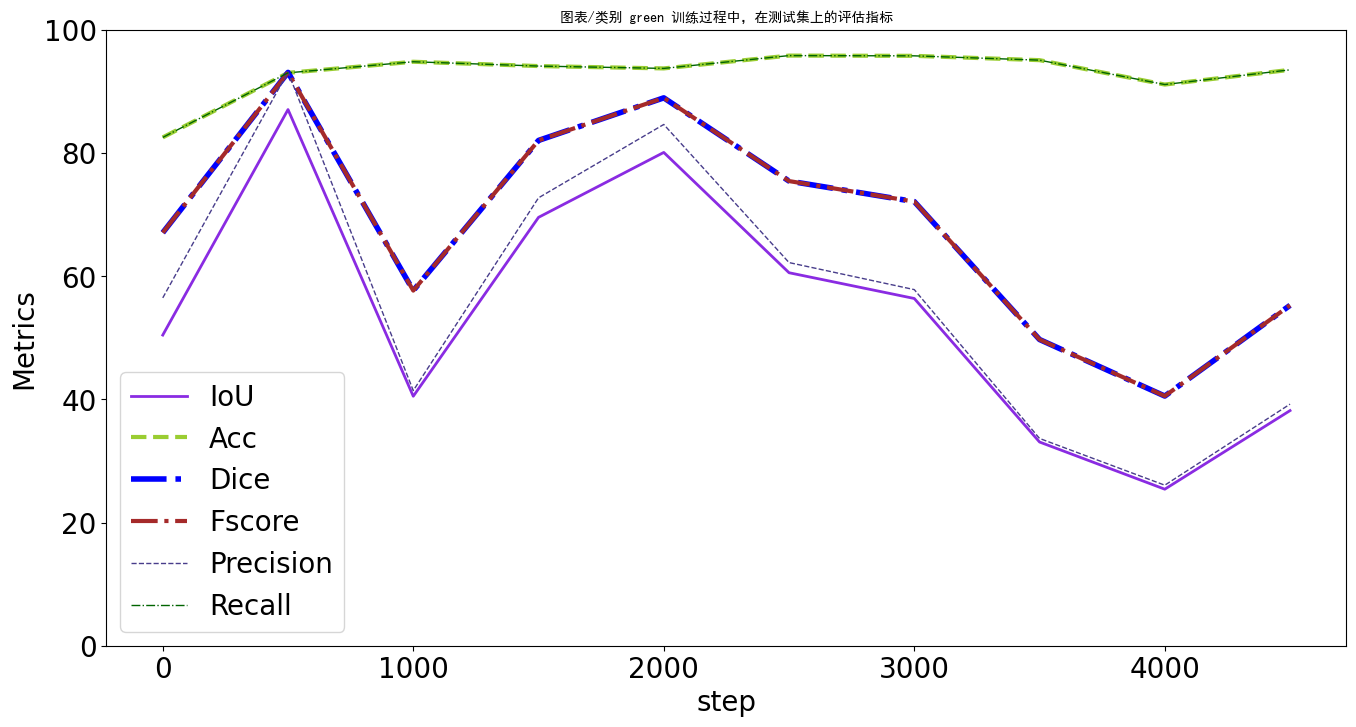
接着对训练过程各类别评估指标进行研究,这里主要涉及六方面元素,即[‘background’, ‘red’, ‘green’, ‘white’, ‘seed-black’, ‘seed-white’],这里单独给出green的图像绘制。可以看到F得分维持在稳定的水平,其他各项指标的变化趋势大致相同。
综上所述,模型的训练结果较好,接下来进行给定模型的测试集评估。(P.S.谷歌云盘上传的速度太慢了,这里直接ondrive转google)
测试集性能评估
在本次训练过程中以PSPNet为基础,因为训练的迭代次数较少,因此在性能评估的结果上和标准模型差距较大。
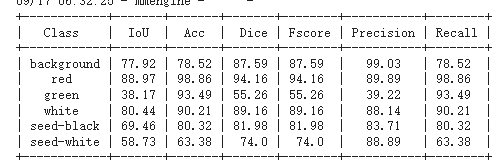


可以看到,在IoU指标上,整体的表现不好,说明在进行测试集关键对象标注时不能近似完全的标注。对于ACC而言,准确率较高,还有一定的提升空间。Dice参数,用于计算两个样本之间的相似度,这里表示成不同类别内部的相似程度,这里和标准模型的差距不是很大,说明模型整体的算法是适合的,但是对于green类别而言需要更多的迭代实现分辨方法的一般性。
训练得到的模型进行预测
这里使用配置文件是基于KNet的实现,对以下图片进行语义分割,对比图如下:

可以看到,西瓜的基本边界以及内部的颜色、西瓜子都实现了较好的分割,这里我们结合图例进行具体的分析。
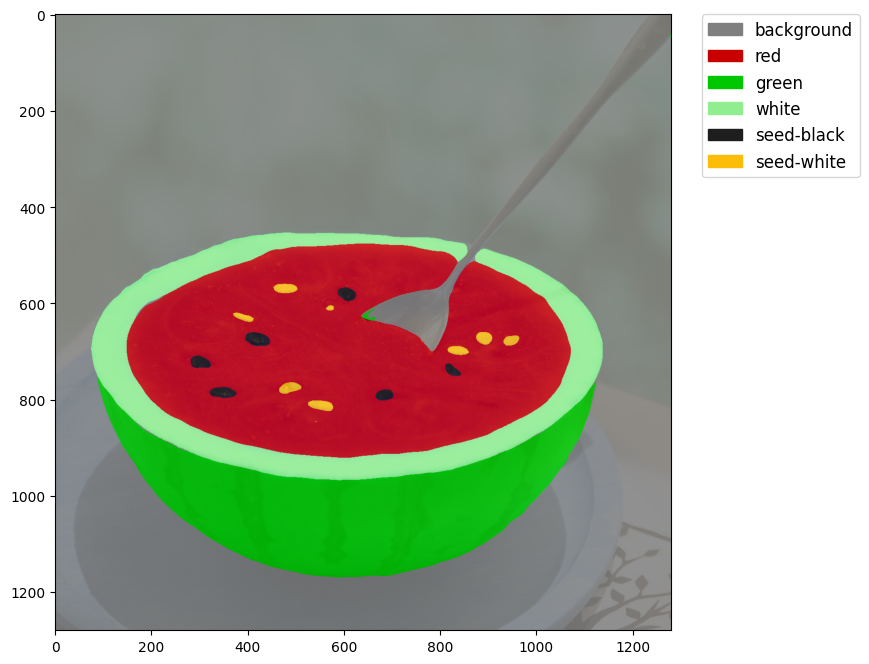
对比原图,我们可以发现当前模型仍旧存在部分问题,如将黑色的西瓜子识别成白色、部分被勺子遮挡的西瓜子没有被识别出来,这些问题都是在以后对模型进行提升时需要注意的。这里还可以实现将特殊部分提取出来,如白色的西瓜子:
生成多个图像进行评估是不现实的,因此这里着重对生成的混淆矩阵进行分析:
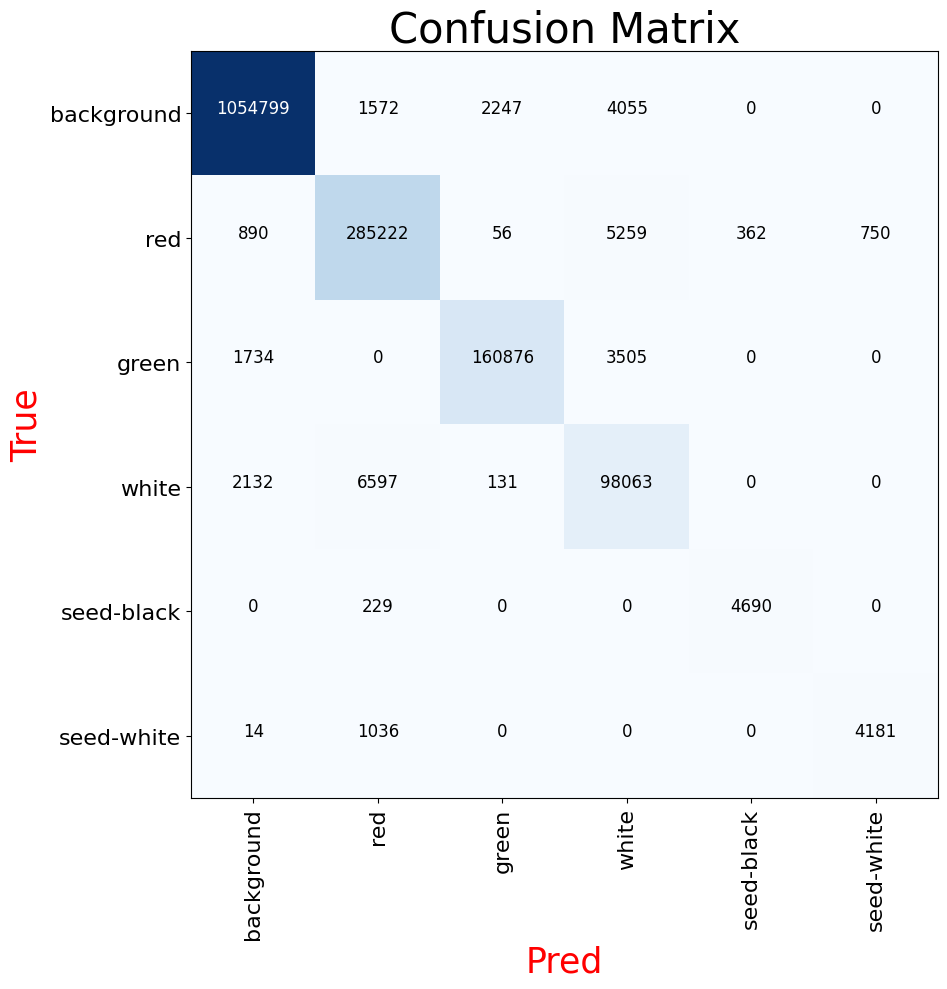
可以看到,识别最为准确的为背景和基本的红色、绿色、白色,而形状最小的西瓜子不容易被识别出来,准确率较低。这也是KNet的简便性的代价。这里可以使用给出的DeepLabv3+模型进行评估,其模型应用的空洞卷积能够更有效地实现小目标检测。
用训练的模型预测视频
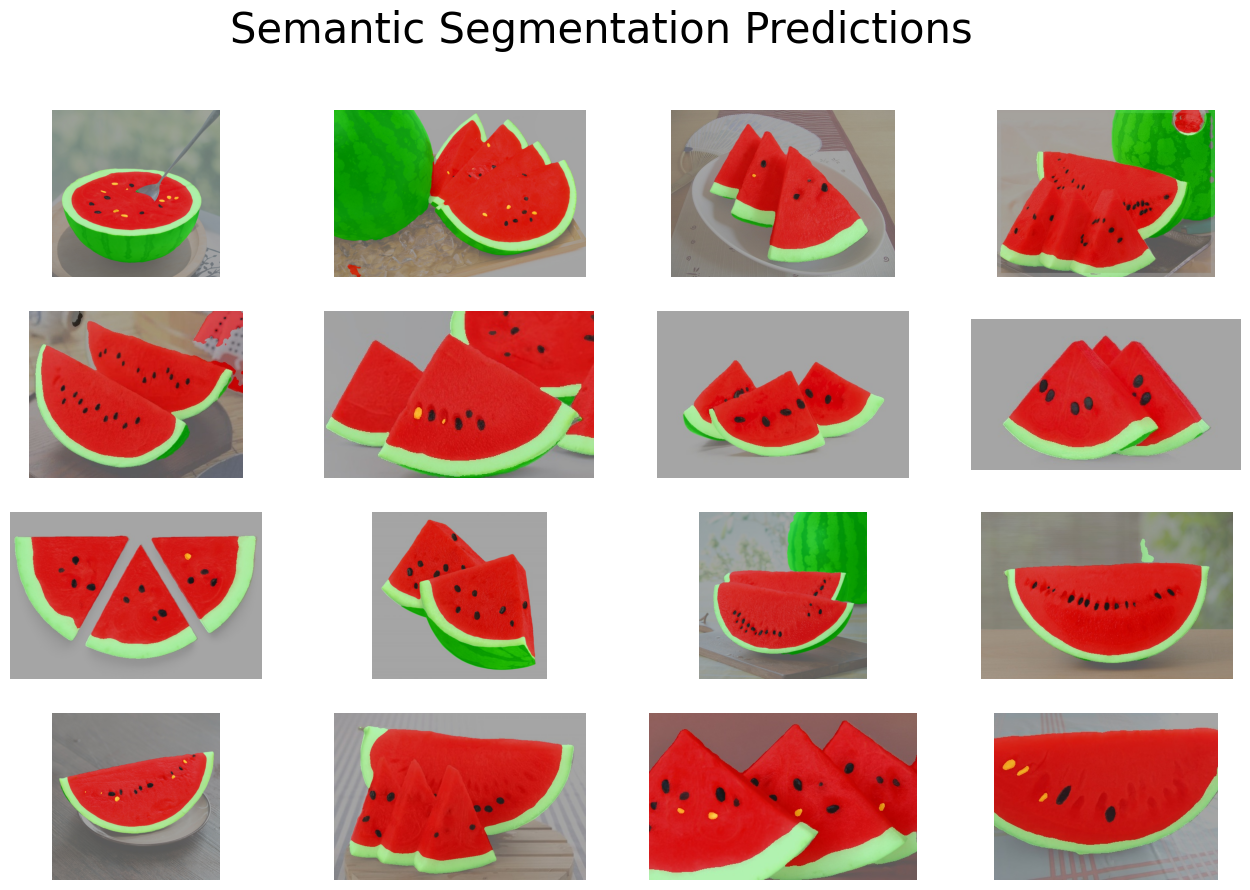
这里不再赘述,就是逐帧进行处理,不是实时的因此比较简单,这里给出对测试集进行多张预测得到的结果:
语义分割部署
这一部分在本地进行相关环境的安装,同时进行摄像头的实时预测。其中使用了MMDeploy这一在线模型转换工具,他提供了一系列工具,帮助我们将OpenMMlab上的算法部署到各种设备和平台上,其基本流程如下图所示:

模型转换的主要功能是吧输入的模型格式进行转换,转换成目标设备的推理引擎所要求的模型格式。在本次实验过程中,我们将模型部署到PC端和手机端,即将Pytorch模型转换为ONNX模型、TorchScript等和设备无关的IR 模型。
本地ONNXRuntime部署
ONNXRuntime是微软推出的一款推理框架,用户可以通过运行其实现基本预测,支持CPU和GPU多种形式,下面对其基本的实现方式进行介绍:
- Session构造:首先创造一个InferenceSession对象,在构造过程中进行各成员的初始化,包括负责OpKernel管理、Session配置信息、图分割、log管理。
- 模型加载初始化:将ONNX模型加载到InferenceSession中进行模型加载、Providers注册以及一系列的内存分配、model partition以及kernel注册。
- 模型运行:每次读入一个batch的数据并进行计算得到模型的最终输出,顺序调用各个node的对应OpKernel进行计算。
本地MMDeploy_Runtime部署
因为前文进行过介绍,这里不再赘述。