机器翻译:基础与模型学习笔记——机器翻译基础
[TOC]
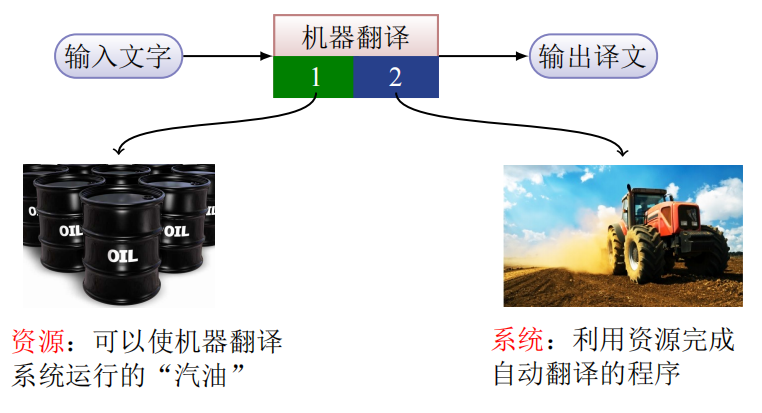
现代翻译系统的基础:从数据中自动学习翻译知识,并运用这些知识对新的文本进行翻译。
机器翻译的发展历程
- 早期:基于书写的规则,存在覆盖范围小、噪声非常敏感的特点;
- 发展:基于数据驱动,即统计机器翻译。机器翻译的建模、训练和推断都可以自动地从数据中学习;
- 爆发:基于神经网络的深度学习方法,存在诸多的优点:
- 端到端学习不依赖于过多的先验假设,避免了某些短语划分产生的对齐问题;
- 表示能力更强,离散化的句子转化为向量表示,更容易处理;
- 算力提升形成基础;
机器翻译现状和挑战
现状:在开放式任务下效果不是很好,无法和人工翻译抗衡。
机器翻译常见方法
基于规则的方法
定义:通过形式文法定义的规则引入源语言和目标语言中的语言学知识,类似于编译器的实现,其基本实现如下图所示,很有编译器前后端的味道。
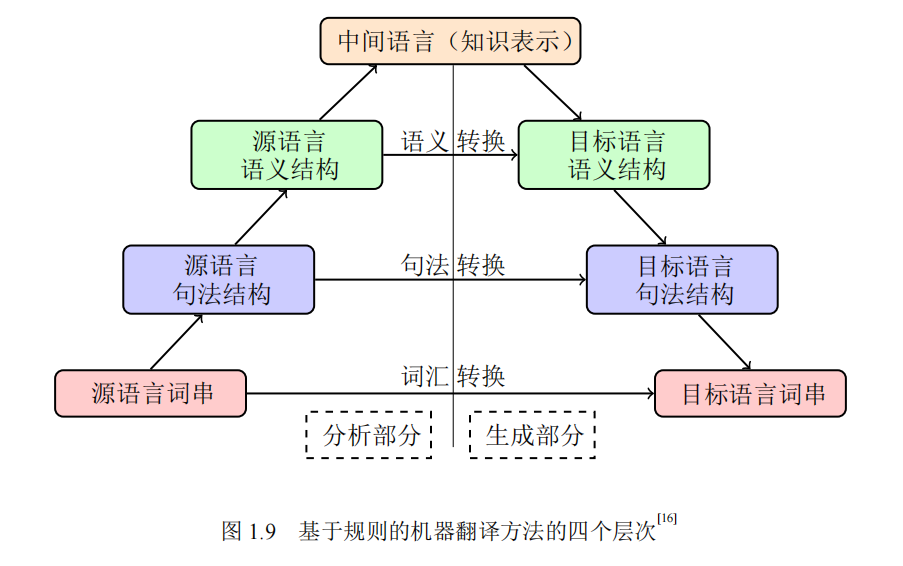
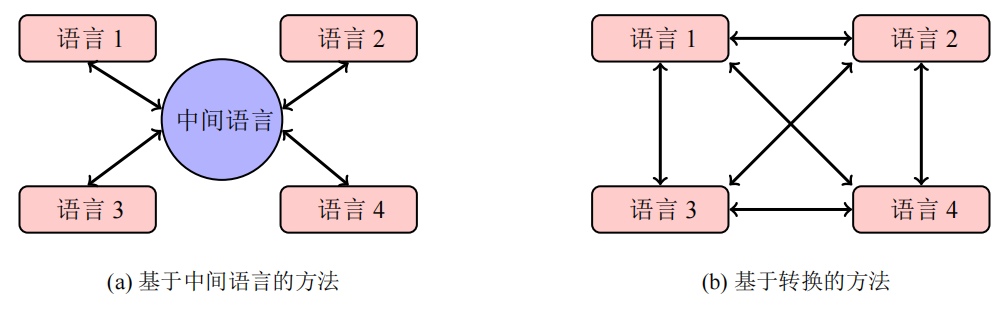
以此为基础,产生了基于转换的方法以及基于中间语言的方法。基于转换的方法就是为每一组特定的源语言和目标语言构建系统,基于上述的词汇层、句法层和语义层实现转换。相较于转换法,中间语言独立于源语言和目标语言,使多个翻译系统实现复用,中间语言方法实现的重要基础使能否充分表达源语言的信息。
优点:
- 语法和算法分离,便于更改;
- 翻译规则的书写颗粒度具有很大的可伸缩性;
- 适用的应用场景多,即大规模系统翻译和小规模精细翻译都可以靠更改规则集实现;
- 规则方法不存在长距离依赖的问题;
缺点:规则维护困难、实现效果较差。
数据驱动的方法
基于实例的机器翻译实现:构建实例库进行源语言匹配,对错误匹配词语进行单独翻译得到最终结果。
基于统计的机器翻译实现:适用单语语料学习语言模型,适用双语平行语料学习翻译模型,并使用这些统计模型实现单一过程的建模,基本实现如下图所示:

神经机器翻译
统计语言建模基础
KL距离和熵
自信息:代表单一事件发生时包含的信息多少。
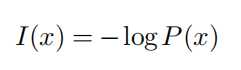
信息熵:量化整个概率分布中的不稳定性或信息量。
KL距离:衡量同一变量不同分布的不同,即相对熵。其物理意义是判断相比于适用概率分布P(X)来编码P(X)时信息量增加了多少。
交叉熵:当概率分布P(X)固定时,求关于Q的交叉熵的最小值等价于求KL距离的最小值,二者都是用来描述两个分布的差异的。

n-gram语言模型
背景:对于单个词语出现的概率,可以使用频率进行替换。但是如何计算句子出现的概率呢?传统的方法分为两种,一方面统计词串出现的次数,利用极大似然估计计算P(低频事件处理不当);另一方面对多个联合出现的事件进行独立性假设,相乘得到最终的结果(破坏单词之间的依赖性)。
定义:利用条件概率实现,每次预测都只考虑前n-1个历史单词,对应马尔科夫模型。

然后需要研究的就是如何计算P(Wm|W1W2…Wm-1)了,如果只是使用条件概率进行估计,很容易出现C(W1W2)=0的情况、或者未出现的未登录词。
平滑
定义:在保证概率和为1的情况下,为0概率事件分配一部分概率;
加法平滑:
古德图灵估计:
重新规定时间发生的次数,原来出现r+1次的统计量设定次数,其中nr代表在语料库中出现r次的n-gram有多少个:
Kneser-Ney平滑方法:
它是通过Absolute Discounting平滑算法推导得到的,公式如下:

这里d代表被裁剪的值,λ是一个正则化常数,这里的P(wi)最初为原始的1-gram概率函数,后续进行提升,可以考虑前一个词的影响评估当前词作为第二个词出现的可能性,归一化之后的公式如下所示:
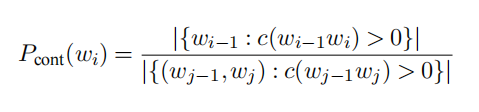
考虑到概率的非负性,对分子进行了约束,最终得到了Kneser-Ney公式:
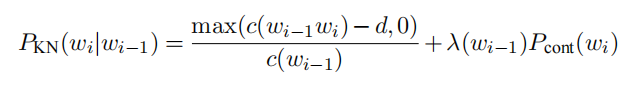
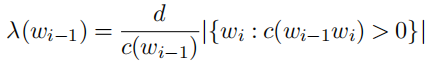
模型最优解搜索
方法:深度优先遍历、广度优先遍历、构建解空间树;
评判优劣方法:完备性、最优性、时间空间复杂度;
序列生成任务:寻找所有单词序列组成的解空间树中权重综合最大的一条路径;
模型评价
困惑度:反应语言模型对序列可能性预测能力的一种评估。
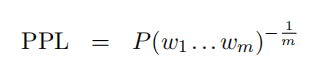
相关性:人工和自动评价之间的相关性,这种性质存在不确定性,对于BLEU方法而言,分数越高并不一定和人工评价的相关性越高,往往会存在一些流利度的问题;
显著性检验:对于提升的评价指标,构建假设检验确定效果是否提升,常用的为BOOSTRAP提升法,构建多个随机测试集重复试验
词法分析和语法分析基础
命名实体:类似于编译原理中的token表的构建,实现和语料的一一对应。想要获取命名实体,序列标注是不可避免的。
序列标注常见策略:
- BIO格式:Begin、inside和outside(非命名实体单元)
- BIOES格式:Begin、inside、outside、end和single
这里引出特征的概念,一个token往往具有很多的特征,在满足了大部分特征时我们才会进行特定token和名词的匹配,因此特征的构建(特征工程)十分重要。
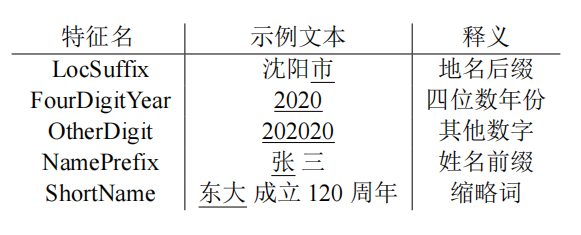
当然,我们也可以根据语料库中已有的词频等信息直接构建概率图模型。
隐马尔科夫模型
**区分隐含和可见:**对于隐马尔科夫模型,首先最重要的是分清什么是隐含状态和可见状态。对于投掷六枚质量不均匀的硬币实验而言,每次投掷之后的实验结果是可见的,而每一枚硬币的正反概率是隐含的。可以说,隐含状态影响可见状态。
两个约束:
- 当前位置的隐含状态和前一个位置的隐含状态相关;
- 当前位置的可见状态和当前位置的隐含状态相关;
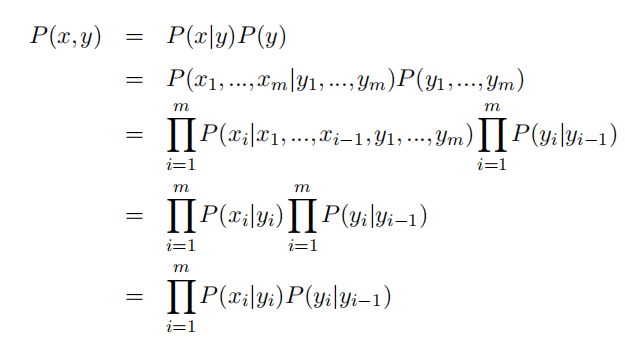
**基本实现:**这里主要讲在中文分词中的应用,对于长度为n的序列,估算转移概率和发射概率,预设n-1个状态,利用前向后向算法更新状态,同时估计模型参数,找到最有可能的预测结果。
翻译质量评价
译文评价的常用标准为流畅度和忠诚度,常用的方法为人工评价和自动评价,实现的基本形式如下图所示:
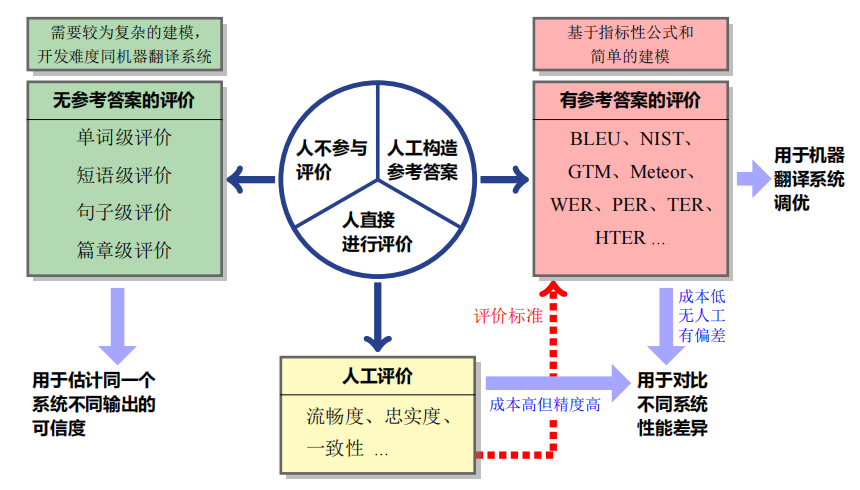
人工评价的基本实现通过打分制或者多系统对抗排名实现的,与之相对的自动评价虽然评价成果较差,但是随着深度学习网络的引入,整体的指导性还是不断提升的。
自动评价
- 存在参考示例的评价:
- 基于距离的方法,根据预测和参考示例的距离进行评价;
- 基于n-gram的BLEU指标:
- 基于词对齐的方法:精确模型->波特词干模型(对精确匹配后的模型进行尚未对齐单词的)->同义词模型;
- 基于检测点的方法:设置检查点数据库,对特殊的多义词、固定搭配短语、特殊句型进行标注,个人感觉类似于注意力机制,对部分检查点进行测试即可;
- 存在多个参考示例的评价:
- HyTER:类似于无穷自动机,构建多个状态的空间转换图,对于同义词组标注多状态,从而规定新的hit标准,然后使用上述的n-gram方法和词对齐方法;
- 分布式方法质量评测:利用词嵌入方法将单词和句子投影到低维空间,使具有相似句法和语义的单词彼此接近。
- 无参考的评价:基于单词质量或者短语质量进行评价;
**基于n-gram的BLEU指标推导过程:**首先继承基于距离的准确率计算方法:
Pn=countoutputcounthit
考虑到存在hit的重复问题,对分子进行截断操作,即:
counthit∗=min(counthit,countoutput)
考虑到短句存在的高分倾向问题,进行惩罚(c代表翻译后的长度,r代表参考长度):
BP={1exp(1−cr)c>rc≤r
最终得到计算结果:
BLEU=BP⋅exp(n=1∑wn⋅logPn)
基于词对齐的Meteor评价方法推导推导,整体公式如下所示:
score=Fmean⋅(1−Penalty)
其中Fmean代表调和均值,是综合召回率和准确率得到的;后一部分为惩罚项,是为了惩罚将原句分割的块数过多导致的语义混乱问题,Penalty的公式如下:
Penalty=0.5⋅(counthitcountchunks)3
其中count_chunks代表匹配的块数,对于Penalty参数而言,匹配的块数越少,证明句子的连贯性越强,能够得到更加稳定的序列。
HyTER方法的基本实现:

词嵌入方法的基本实现方法(投影实现的基本方法):

相关知识
长距离依赖问题
长距离依赖问题根本上是前馈神经网络产生了梯度消失的问题,在机器翻译中的问题就是无法结合之前的语境做出正确的预测。这一点有点像之前在进行vqa论文复现时存在的问题。例如,给出一张绿色香蕉的图片,询问香蕉颜色。由于在训练过程中的数据图片以及fvqa的结果都是黄色香蕉,因此得到了错误的回答。回到长距离依赖问题上。
分布越尖锐熵越低,分布越均匀熵越高
对于概率分布而言,取极端的情况,只有两种事件发生,概率分别为0和100%,显然只会发生第二件事,因此这个分布包含的信息就很少,信息熵较低。
偏置(bias)
一个英文单词的翻译结果可能往往就是那几个词,不仅要学习这种偏置,还需要避免偏置在测试集的某些特殊情况下产生错误。
未登录词(OOV Word)
什么是未登录词 Out-of-vocabulary(OOV)?-CSDN博客
Forward-Backward Algorithm
HMM(1)—概率计算问题,前向后向算法 - 知乎 (zhihu.com)
可以具体推导一下,感觉还是可以的,大概明白了前向和后向的算法实现。
EM算法
EM算法详解 - 知乎 (zhihu.com)
相关学术会议
- AACL,全称 Conference of the AsiaPacific Chapter of the Association for Computational Linguistics.
- ACL,全称 Annual Conference of the Association for Computational Linguistics
- EMNLP,全称 Conference on Empirical Methods in Natural Language Processing
Future Work
- 平滑方法的拓展;
- 基于n-gram的超大规模数据进行语言模型训练;
- 命名实体的更多新思路:隐马尔科夫模型、条件随机场、最大熵和支持向量机;
- 自动翻译和人工翻译的相关性研究,自动翻译的流利度评价问题,以及如何解决;