机器翻译:基础与模型学习笔记——机器翻译前沿
神经机器翻译模型训练
神经机器翻译在当代遇到问题常有以下三部分:
- 对大容量模型的有效训练,也就是数据集的构建和过拟合之间的矛盾;
- 如何更好地训练模型,也就是特征选择和评价指标的判断标准;transformer固然提高了某些评估标准,但是与人工翻译的结果还是存在差距;
- 如何将模型进行迁移,也就是知识迁移、知识蒸馏;
开放词表——数据集的构建
理想情况下机器翻译应该是一个开放词表的翻译任务,但是面对大词表和未登录词两个问题,很难得到泛用的数据集。
- 大词表:数据稀疏,词嵌入随时态变化较多;词嵌入得到的向量大小随词表的数据量增大而增大,softmax层压力比较大;
- 未登录词:影响后续的翻译质量,出现欠翻译、结构混乱等问题;
为了解决以上的几种问题,提出了以下三种方法:
子词:既然开放词表中的数据较多,那么缩小翻译单元会减少翻译的类别,从而减缓sofrmax层的压力。这里就是对单词进行前后缀的拆分。

相较于之前的token表,多了一个合并关系表,根据合并关系将前后缀合并为子词。
双字节编码:方法和子词类似,首先计算词表各词的出现频率,接着统计二元组的出现频次,将频次最高的二元组加入符号合并表,如此往复直到没有二元组可以被合并。唯一和子词不同的是将常见的连续字符串替换成不存在的字符后构建对应表,相当于对空间进行了压缩。
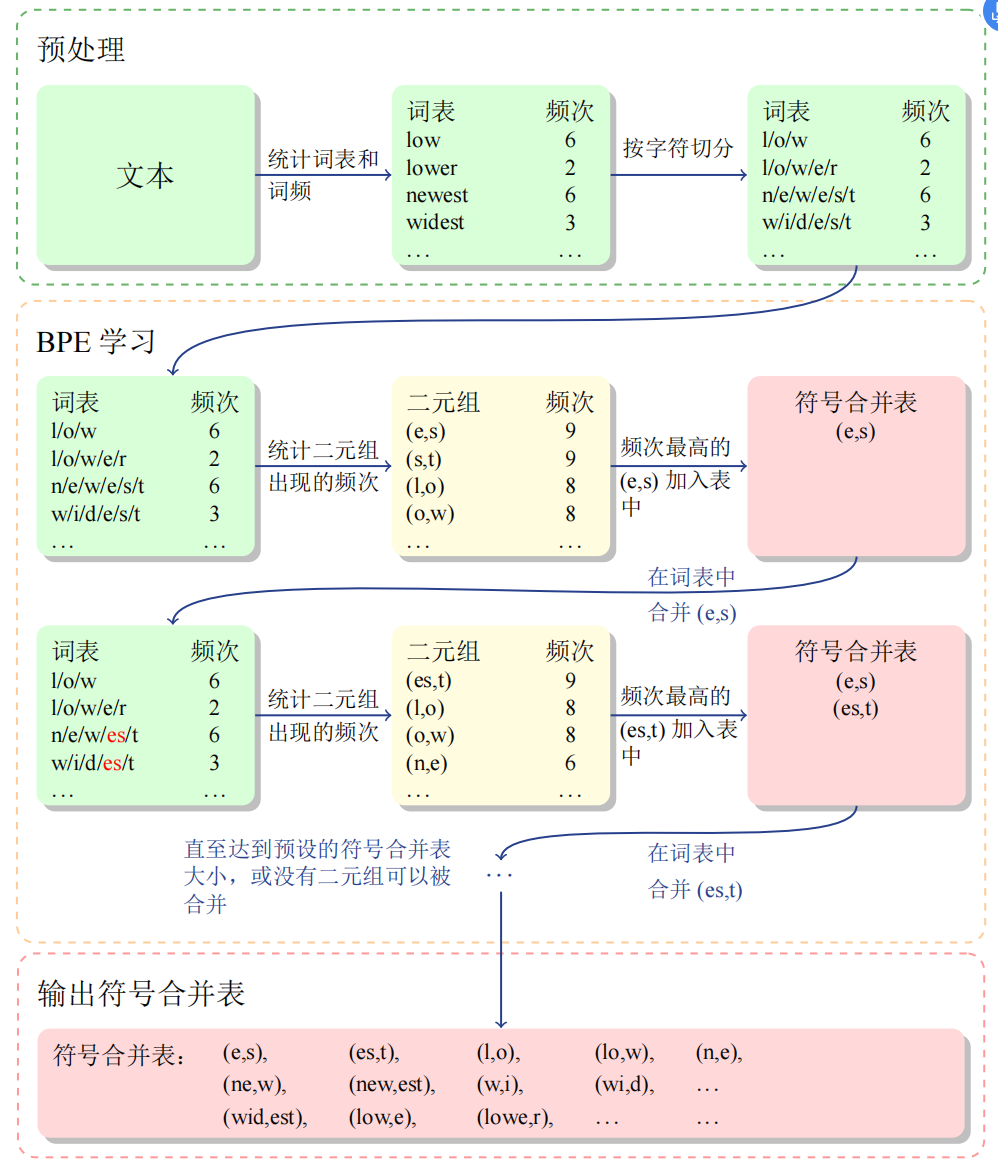
**其他方法:**其他方法也是基于上述实现,不过做了些许改进:
- 子词规范法:根据1-gram模型采样出多种子词切分候选;
- BPE-Dropout:一定概率抛弃一些可行操作,产生不同的子词切分结果;
- 动态规划编码:没看懂,这里是对混合字符-子词进行切分,将句子的子词切分看做一种隐含的变量;
正则化——针对过拟合问题
在传统的机器学习模型中,正则化往往是针对过拟合问题的方法。过拟合的产生往往是源于以下两个因素:
- 观测数据不充分,也就是样本丰富度的问题,这一点可以通过扩充数据集实现;
- 数据中存在噪声,正则化的存在就是防止曲线完美拟合噪声点;
w=argminwLoss(w)+λR(w)
常见的L1、L2正则就不再说了,感觉基于之前提到的范数都可以进行实验和规范。下面介绍两种常见的正则方法:
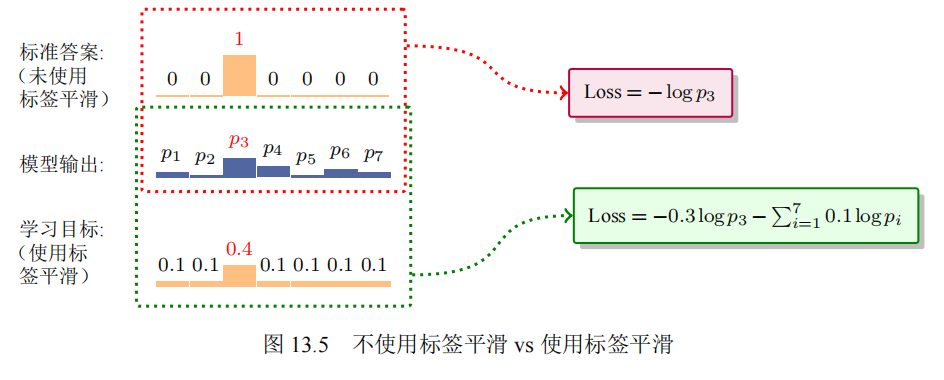
标签平滑:在目标语言某个位置存在一个分布,用来描述目标语言生成概率。如果基于onehot分布很容易产生两个问题,一是同义词出现概率高但是被认为是错误的;另一个就是不同位置之间的相关性关系在onehot分布中表现不明显。
yjls=(1−α)⋅yj+α⋅q
因此标签平滑软化了预测指标,加入了基于词表的均匀分布,通过控制系数α进行惩罚,从而降低噪声影响,使分布更加合理。
dropout:神经元之间存在相互适应的问题,即同一层的不同神经元的输出和彼此的行为相关,从而导致训练结果一致,面对测试集输出同样的错误答案。dropout让一部分神经元停止工作。
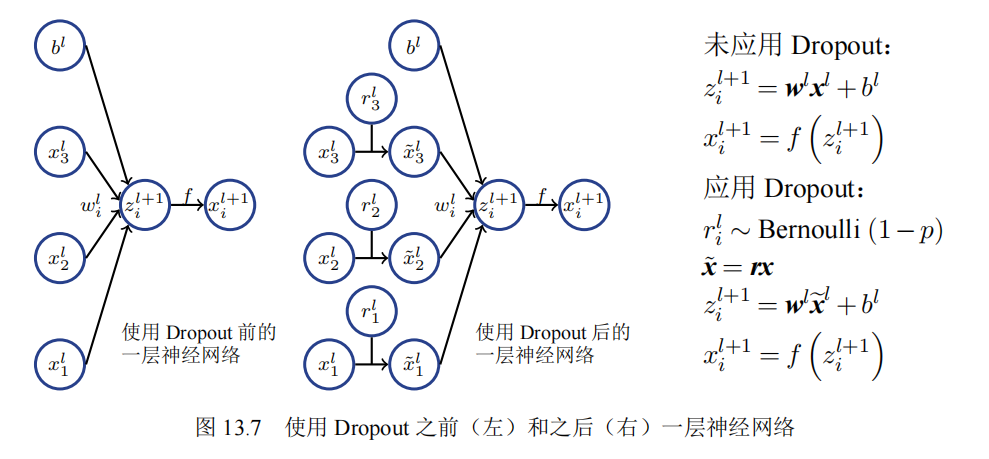
基本原理:首先给定前提,即每个神经元都有p概率停止工作,在训练过程中采用伯努利分布以概率p随机将输入张量中的一些元素置0,同时需要注意的是训练得到的结果需要除以1-p,保证和测试集结果相近。(Dropout - 知乎 (zhihu.com))
对抗样本训练——针对特征选择的漏洞
个人理解就是给出逆训练集分布的测试集,从而完成攻击。对抗样本形式上可以被描述为:
C(x)=yC(x′)=ys.t.Ψ(x,x′)<ε
常见的攻击方法有黑盒和白盒:
**基于黑盒的攻击方法:**拼写错误、语法错误;交换、插入、替换、删除词语(FGSM算法计算贡献度)
基于白盒的攻击方法:
- 输入端:输入词嵌入呈现正态分布、词嵌入划分发音序列后再组合新的词嵌入;
- 梯度传输:候选词梯度之间相似度构建样本;
学习策略——评价指标的确定
背景:传统的最大似然法存在曝光偏置的问题(模型依赖于标注数据),于是探求非Teacher-forcing方法,即依赖于上一时刻的模型输出作为下一个时刻的输入。
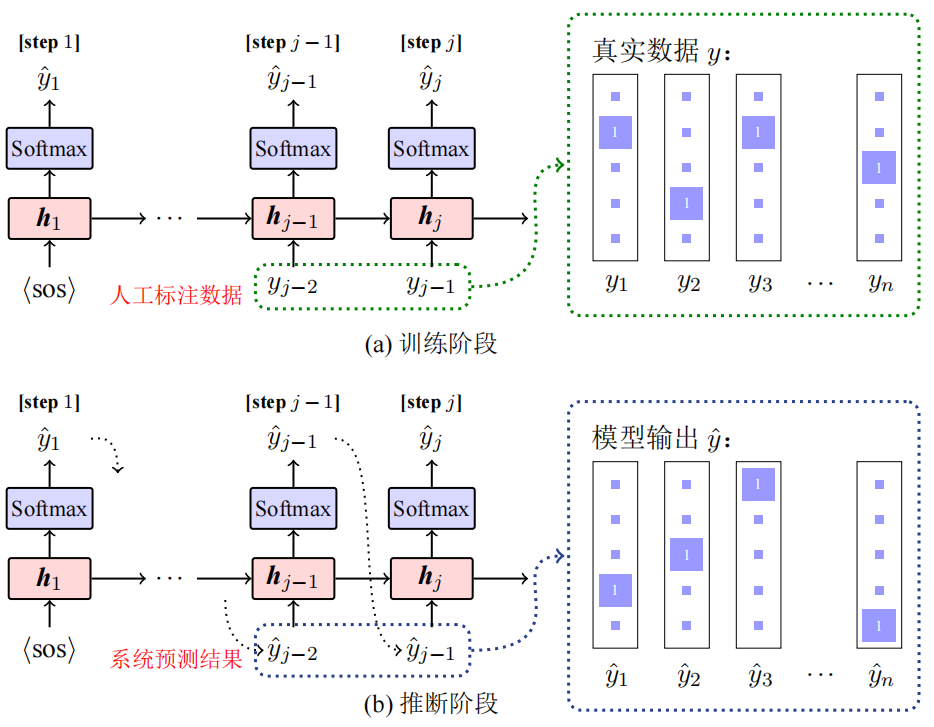
针对以上问题,常用以下三种方法解决:
**调度采样:**模型学习循序渐进,前期使用标注训练,结果逐渐收敛的后期使用模型自身预测的结果进行训练,基本方法包括线性衰减、指数衰减和反向Sigmoid衰减;
**生成对抗网络:**判别网络判断输入的预测的y和目标语言的y是否正确匹配,然后生成信号促进生成模型进一步生成更准确的y。
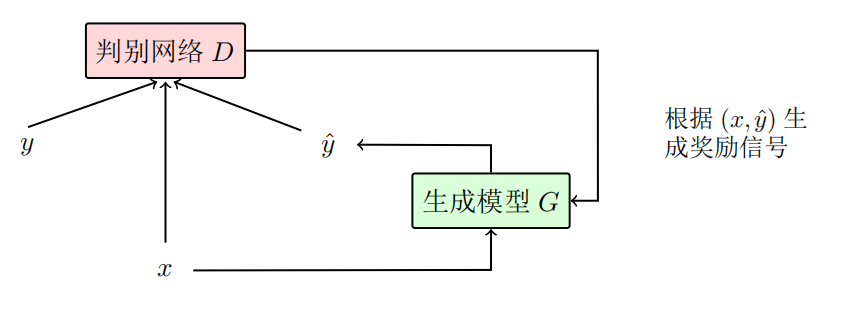
强化学习:
相关知识
FGSM算法
神经网络中对抗攻击的基本概念和FGSM/PGD算法原理 - 知乎 (zhihu.com)
FGSM是一种对抗攻击方法,对模型输入的梯度进行一定限度的扰动,使得扰动后的损失函数最大。
x′=x+ϵ⋅sign(∇xL(x,y;θ))
后面一项就是在参数确定的情况下(如w,b),损失函数L变化情况。
Future Work